




Spis treści
EleutherAI publikuje Common Pile v0.1 – zbiór danych treningowych oparty wyłącznie na licencjach otwartych
Organizacja badawcza EleutherAI we współpracy z University of Toronto, Hugging Face i innymi instytucjami opublikowała Common Pile v0.1 – 8 terabajtowy zbiór danych składający się wyłącznie z tekstów w domenie publicznej i treści na licencjach otwartych. Ten bezprecedensowy projekt ma na celu udowodnienie, że możliwe jest trenowanie wydajnych modeli językowych bez wykorzystywania materiałów chronionych prawem autorskim, co stanowi odpowiedź na narastające kontrowersje prawne w branży sztucznej inteligencji.
Specyfikacja techniczna i wydajność modeli
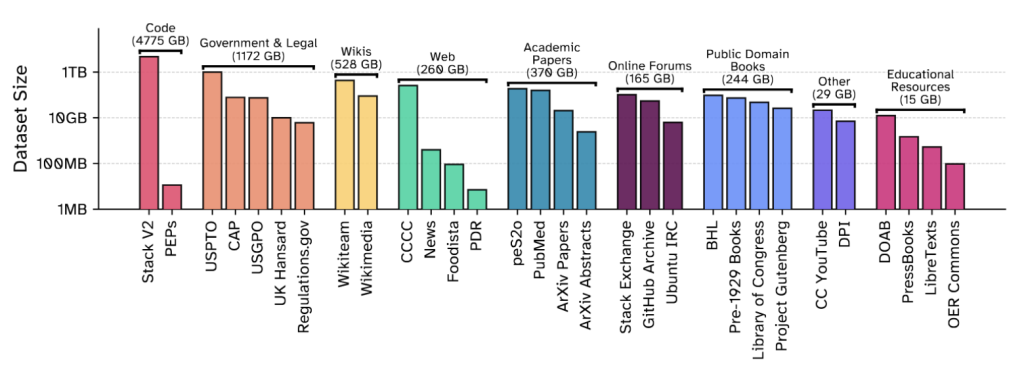
Common Pile v0.1 zawiera treści z 30 różnorodnych źródeł, obejmujących artykuły naukowe z arXiv i PubMed Central, książki z domeny publicznej z Library of Congress, materiały edukacyjne, kod źródłowy oraz transkrypcje audio. Dataset przeszedł rygorystyczne sprawdzenie licencyjne zgodnie z Open Definition 2.1, wykluczając wszelkie treści z ograniczeniami komercyjnymi lub zakazem tworzenia dzieł pochodnych. Organizacja wykorzystała ten zbiór do wytrenowania dwóch modeli: Comma v0.1-1T (trenowany na 1 biliona tokenów) i Comma v0.1-2T (2 biliony tokenów), każdy z 7 miliardami parametrów.
Testy porównawcze wykazały, że modele Comma osiągają wydajność porównywalną z modelami trenowanymi na nielicencjonowanych danych, takimi jak pierwotny LLaMA od Meta. W benchmarkach obejmujących programowanie, rozumienie obrazów i matematykę, modele uzyskały wyniki konkurencyjne względem istniejących rozwiązań o podobnym budżecie obliczeniowym.
Praktyczne zastosowania i znaczenie dla branży
Publikacja Common Pile v0.1 ma kluczowe znaczenie dla firm technologicznych borykających się z pozwami sądowymi dotyczącymi naruszenia praw autorskich. Stella Biderman, dyrektor wykonawczy EleutherAI, argumentuje, że procesy sądowe drastycznie zmniejszyły transparentność firm AI, utrudniając badania nad działaniem modeli. Dataset dostępny na Hugging Face i GitHub oferuje alternatywę dla przedsiębiorstw poszukujących etycznych źródeł danych treningowych. Projekt stanowi także fundament dla przyszłych inicjatyw zmierzających do budowy większych i lepszych zbiorów danych opartych na licencjach otwartych, potencjalnie przekształcając sposób trenowania kolejnych generacji modeli językowych.
Platforma Capsa: Rewolucja w zarządzaniu niepewnością modeli sztucznej inteligencji
Systemy sztucznej inteligencji, takie jak ChatGPT, potrafią generować przekonujące odpowiedzi na niemal każde pytanie, jednak rzadko ujawniają luki w swojej wiedzy lub obszary niepewności. Problem ten może mieć poważne konsekwencje w zastosowaniach krytycznych, gdzie AI wykorzystywane jest do opracowywania leków, syntezy informacji czy sterowania pojazdami autonomicznymi.
Technologia wykrywania niepewności
Startup Themis AI, wywodzący się z MIT, opracował platformę Capsa, która automatycznie quantyfikuje niepewność modeli uczenia maszynowego i koryguje niepewne wyniki w ciągu sekund. System działa poprzez modyfikację modeli AI, umożliwiając im wykrywanie wzorców w przetwarzaniu danych wskazujących na dwuznaczność, niekompletność lub bias. Platforma może współpracować z dowolnym modelem uczenia maszynowego bez konieczności znaczących zmian inżynieryjnych.
Kluczową innowacją jest algorytm “wrappingu”, który otacza istniejący model dodatkową warstwą analityczną. Ta warstwa monitoruje procesy decyzyjne modelu i identyfikuje sytuacje, w których przewidywania mogą być niewiarygodne. Technologia rozróżnia między niepewnością aleatoryczną (wynikającą z nieodłącznego szumu w danych) a niepewnością epistemiczną (związaną z ograniczoną wiedzą modelu).
Zastosowania praktyczne
Platforma Capsa znajduje zastosowanie w wielu branżach wysokiego ryzyka. W farmacji pomaga ocenić, czy przewidywania modeli dotyczące kandydatów na leki opierają się na rzeczywistych dowodach czy jedynie na spekulacjach. W telekomunikacji wspiera planowanie sieci i automatyzację, podczas gdy w przemyśle naftowym pomaga interpretować obrazy sejsmiczne.
Szczególnie obiecujące jest zastosowanie w edge computing, gdzie mniejsze modele działające na urządzeniach mobilnych mogą przekazywać niepewne zadania do centralnych serwerów, zachowując jednocześnie niskie opóźnienia. Dodatkowo, firma bada możliwości integracji z technikami chain-of-thought reasoning w dużych modelach językowych, co może znacząco poprawić ich wydajność i zmniejszyć wymagania obliczeniowe.
FlowGram.AI – Open Source’owy Silnik do Tworzenia Wizualnych Workflow
FlowGram.AI to innowacyjne narzędzie open-source opracowane przez ByteDance, które umożliwia deweloperom szybkie tworzenie wizualnych przepływów pracy w oparciu o architekturę węzłową. Platforma wyróżnia się elastycznością oferując dwa różne tryby pracy oraz koncentracją na integracji z możliwościami sztucznej inteligencji.
Architektura i Funkcjonalności Techniczne
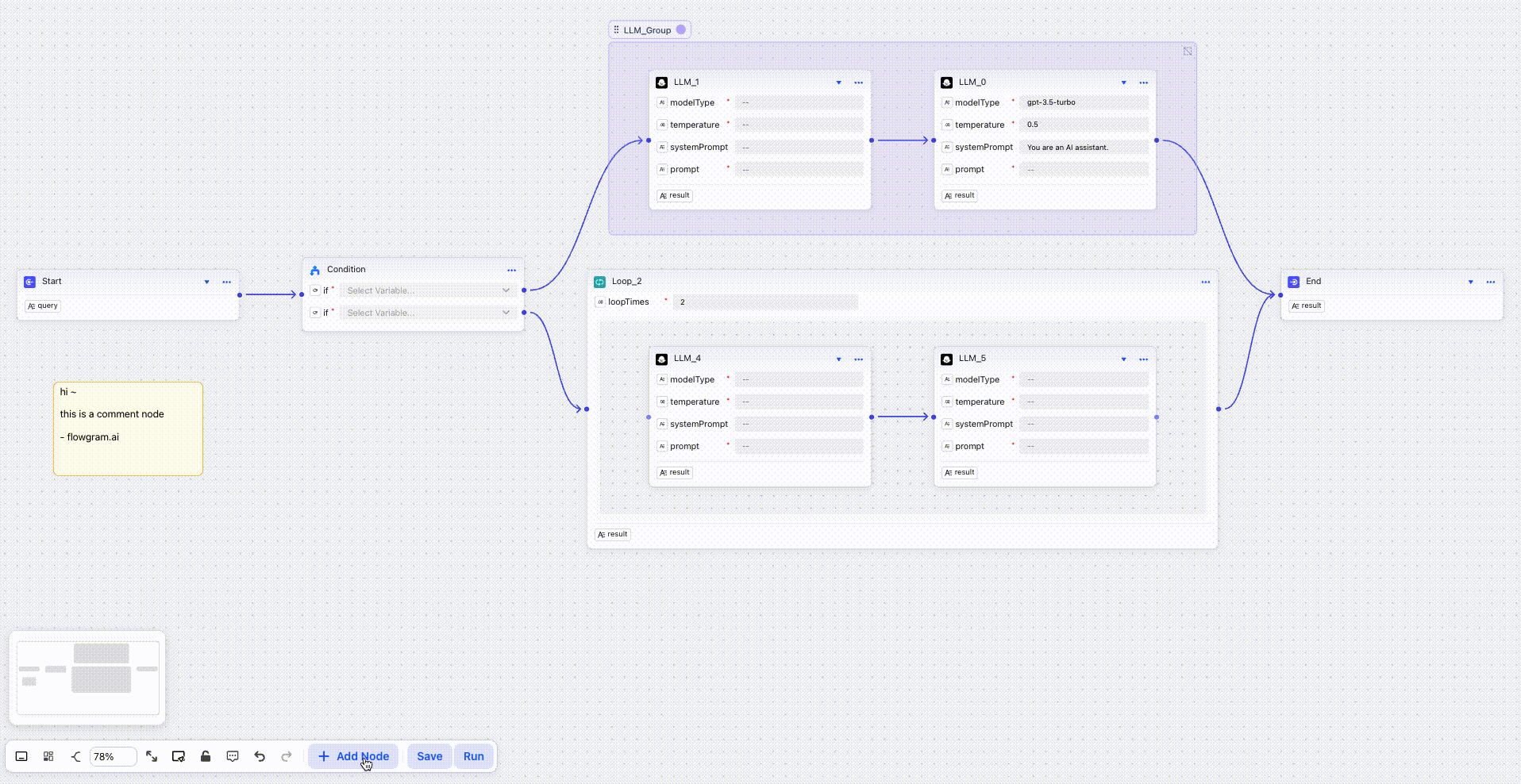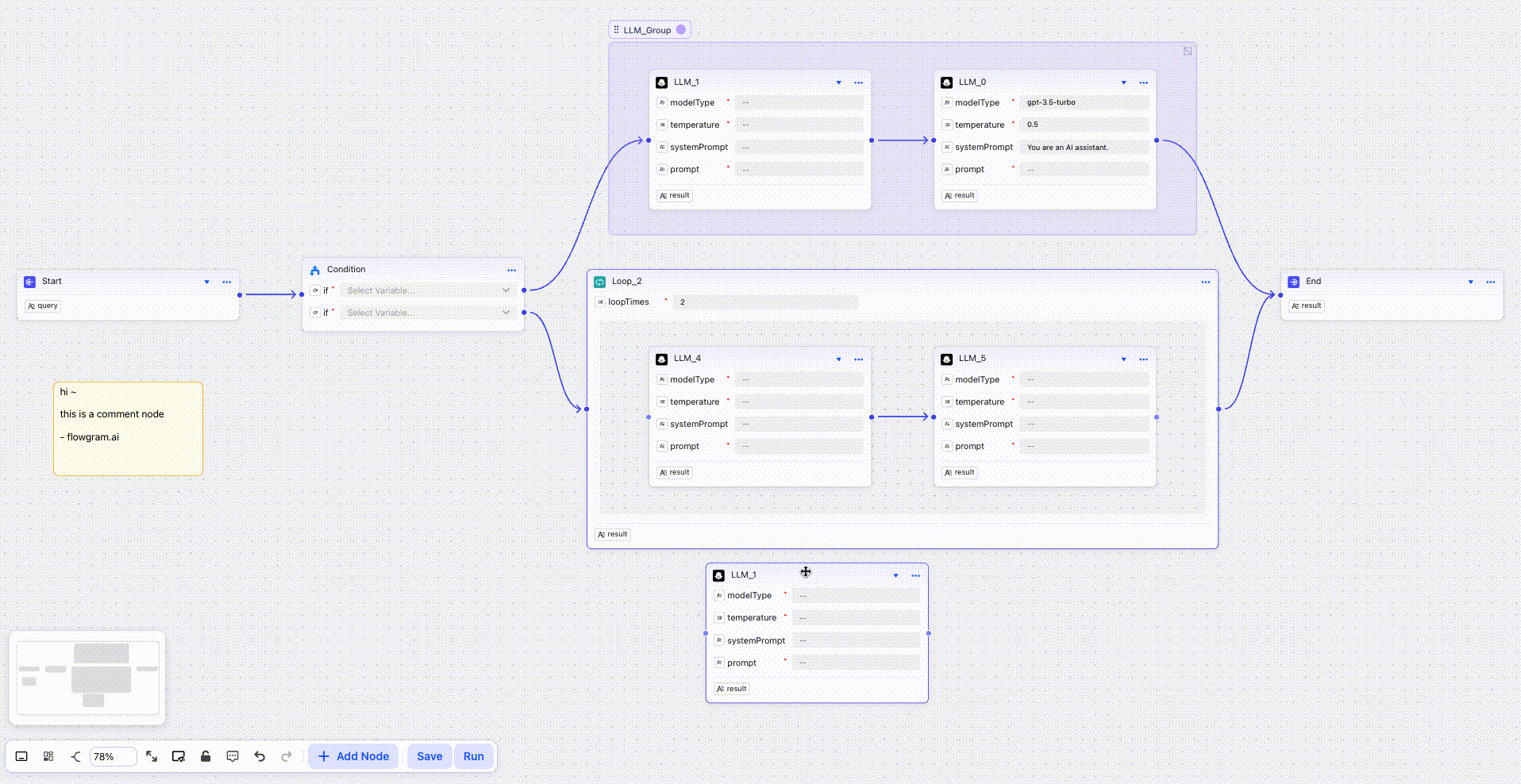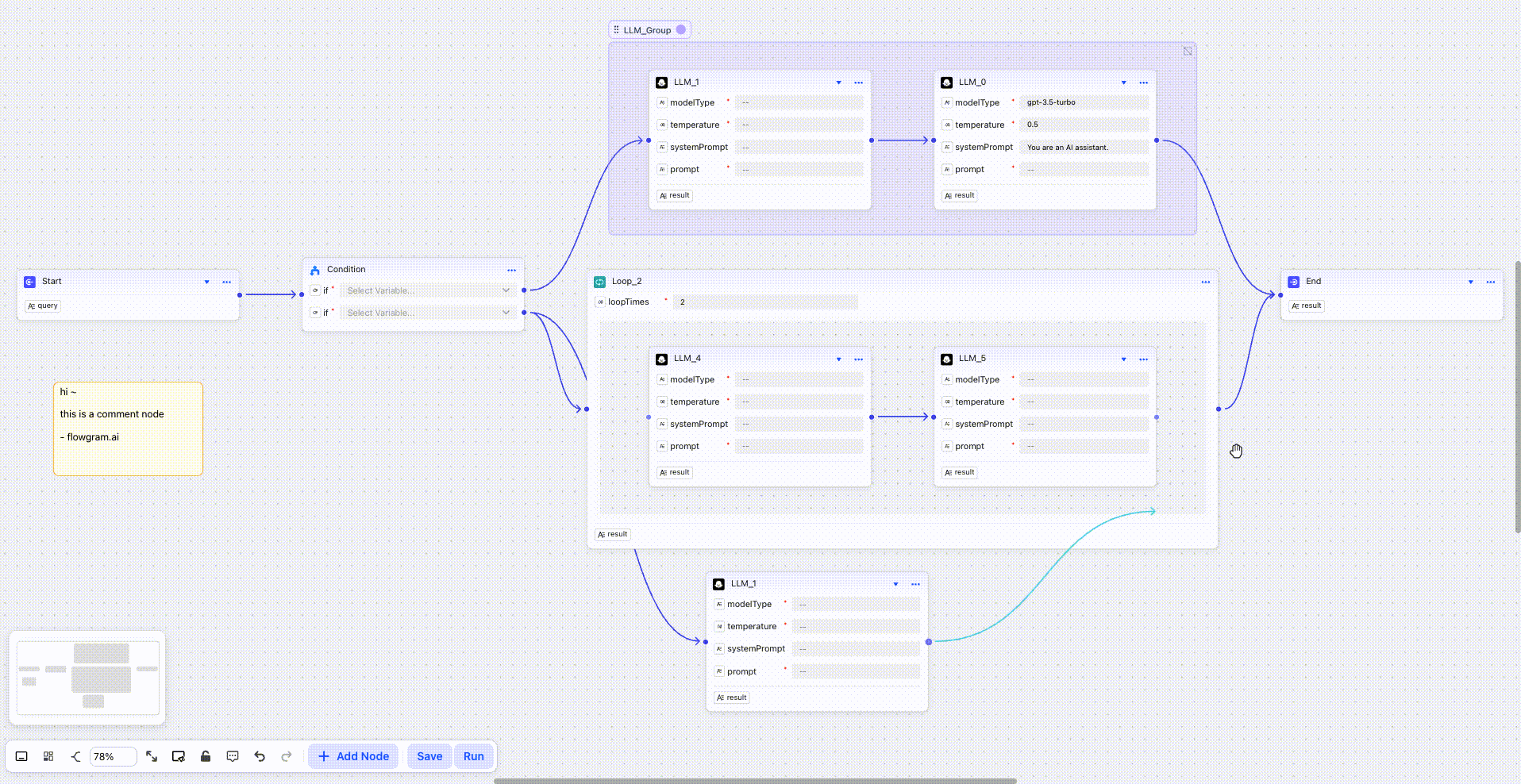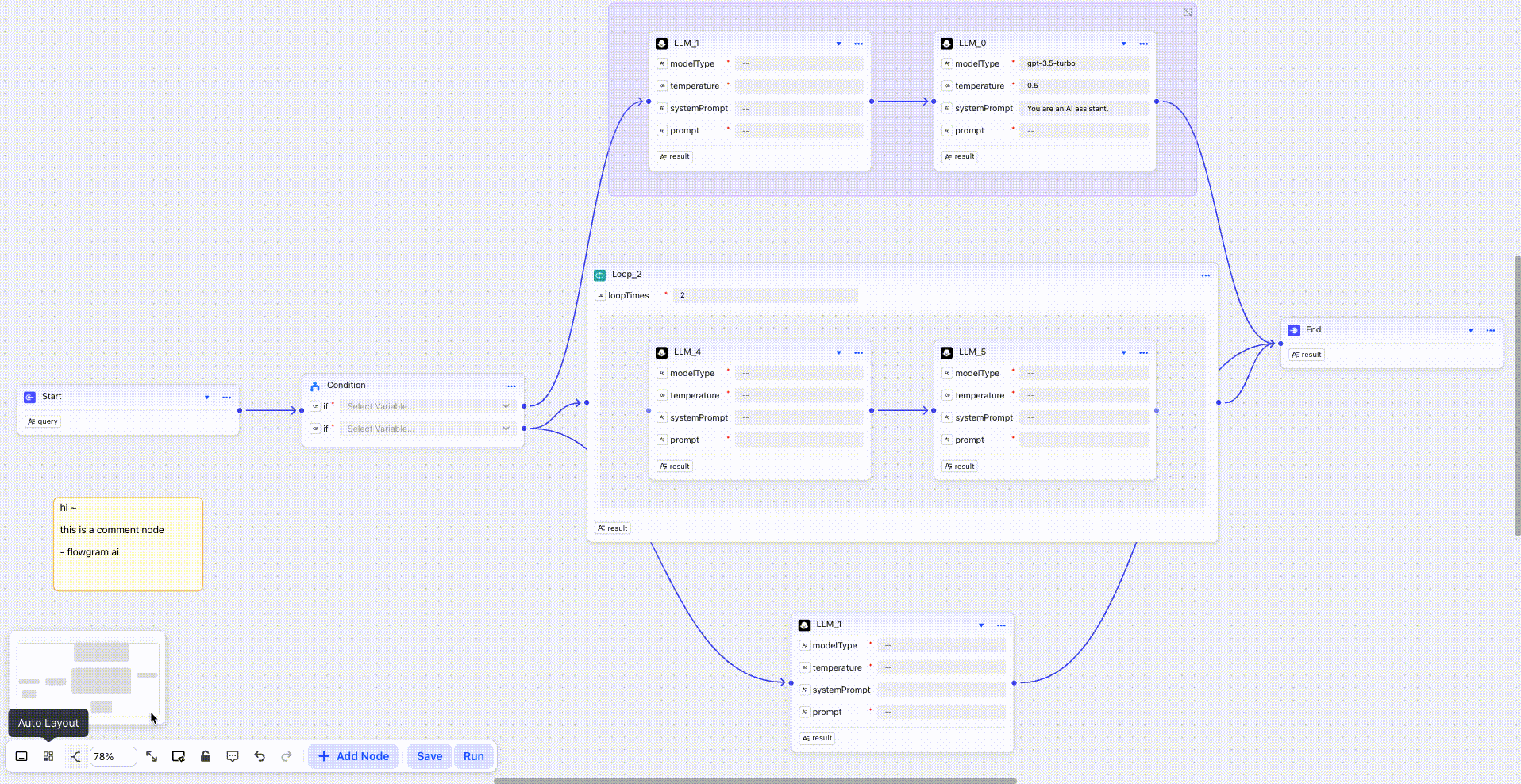
Platforma została zbudowana w oparciu o nowoczesny stos technologiczny, gdzie TypeScript stanowi 83% kodu bazowego, uzupełniony przez MDX (12,7%) oraz JavaScript (3,1%). FlowGram.AI oferuje deweloperom dwa fundamentalne tryby pracy dostosowane do różnych scenariuszy zastosowań. Pierwszy to Fixed Layout, gdzie węzły mogą być przeciągane do określonych pozycji z obsługą złożonych struktur takich jak rozgałęzienia i pętle. Drugi tryb, Free Layout, umożliwia swobodne pozycjonowanie węzłów w dowolnych miejscach z możliwością łączenia ich za pomocą elastycznych linii połączeń.
System pakietów został zorganizowany w modułowej strukturze obejmującej @flowgram.ai/create-app do tworzenia aplikacji, @flowgram.ai/fixed-layout-editor dla edytora uporządkowanego oraz @flowgram.ai/free-layout-editor obsługującego swobodny układ. Platforma wymaga Node.js w wersji 18 lub wyższej oraz wykorzystuje PNPM jako menedżer pakietów wraz z Microsoft Rush do zarządzania monorepozytorium.
Praktyczne Zastosowania w Rozwoju Oprogramowania
FlowGram.AI znajduje szerokie zastosowanie w projektach wymagających wizualizacji złożonych procesów biznesowych, automatyzacji przepływów pracy oraz tworzenia systemów low-code i no-code. Szczególnie przydatne okazuje się w przypadku workflow z jasno zdefiniowanymi wejściami i wyjściami, gdzie wizualna reprezentacja znacznie ułatwia zrozumienie logiki aplikacji. Narzędzie może być wykorzystywane do tworzenia diagramów przepływu danych, automatyzacji procesów oraz jako fundament dla aplikacji opartych na graficznym interfejsie użytkownika.
Źródła
- FlowGram.AI – GitHub Repository
- EleutherAI releases massive AI training dataset of licensed and open-domain text – TechCrunch
- The Common Pile v0.1 – EleutherAI Blog
- The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text – arXiv
- Announcing the Common Pile and Comma v0.1 – Hugging Face
- Teaching AI models what they don’t know | MIT News
- Themis AI’s Capsa Platform: Teaching AI Models to Recognize Their Limitations
- A Unified Framework for Quantifying Risk in Deep Neural Networks
- Capsa – Themis AI



