




Współczesna sztuczna inteligencja coraz częściej napotyka ograniczenia związane z brakiem dużych, dobrze oznaczonych zbiorów danych potrzebnych do uczenia modeli. Metody few-shot learning oraz zero-shot learningstanowią odpowiedź na te wyzwania, umożliwiając skuteczne uczenie modeli nawet przy minimalnych, a czasem zerowych wymaganiach dotyczących liczby przykładów.
Podstawy uczenia z ograniczonymi danymi: czym są few-shot i zero-shot learning?
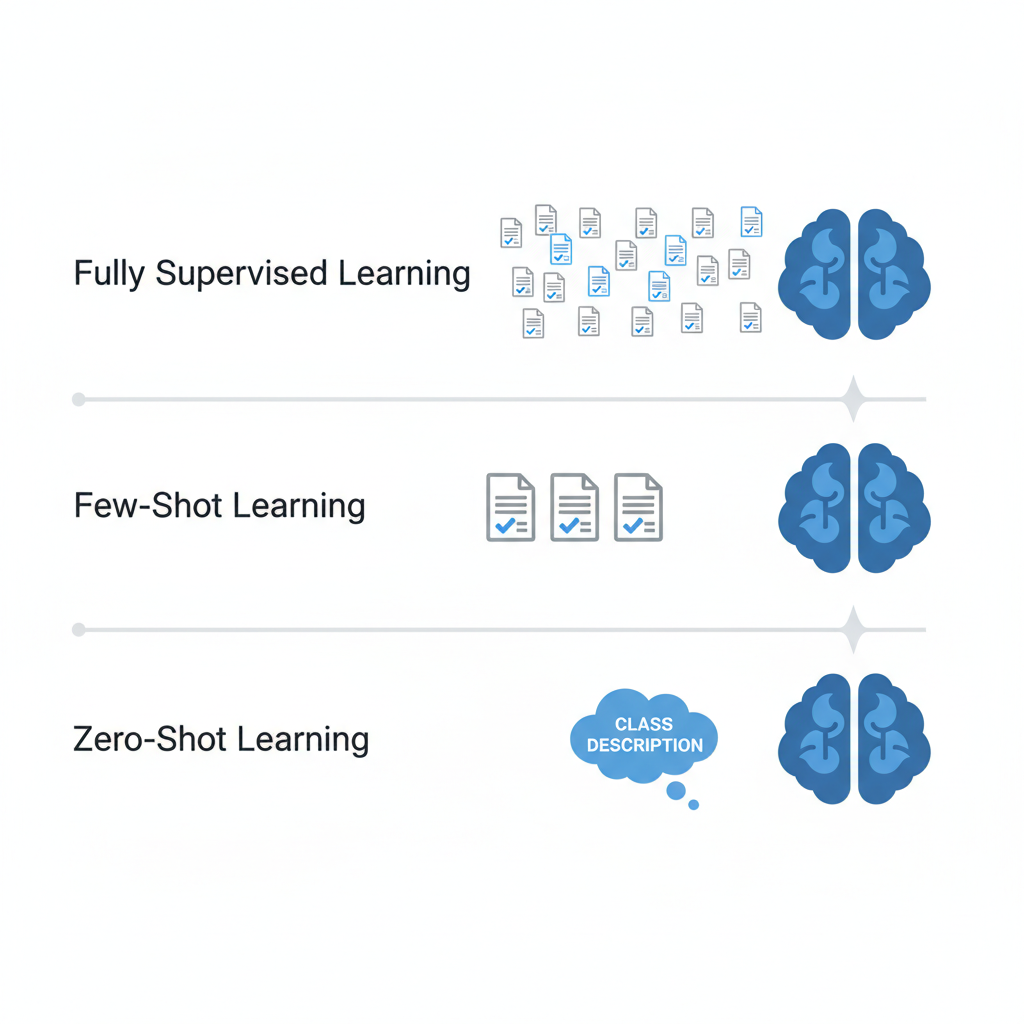
Few-shot learning to podejście, które umożliwia modelom uczenie się nowych zadań na podstawie jedynie kilku oznaczonych przykładów. Działa na zasadzie meta-uczenia, czyli „uczenia się jak się uczyć” — model po przetrenowaniu na wielu różnych zadaniach potrafi generalizować i szybko adaptować się do zupełnie nowych kategorii, nawet jeśli otrzyma jedynie 2–5 przykładów danej klasy. Przykładowo, w detekcji rzadkich chorób medycznych model jest w stanie rozpoznać nową jednostkę chorobową po analizie zaledwie kilku obrazów rentgenowskich.
Zero-shot learning idzie o krok dalej — umożliwia rozpoznawanie lub klasyfikację całkowicie nowych klas, których model nie widział nigdy wcześniej, bazując wyłącznie na deskrypcji tych klas (np. opis słowny, wektor cech). W tym przypadku model korzysta z wiedzy zgromadzonej podczas uczenia na dużych i różnorodnych zbiorach danych (np. obrazy, teksty) i przenosi ją na zupełnie nowe zadania.
| Typ uczenia | Liczba przykładów | Opis |
|---|---|---|
| Fully supervised | setki–tysiące | Tradycyjne uczenie, duże zbiory oznaczonych danych |
| Few-shot | 2–5 | Niewielka liczba przykładów na klasę, szybka adaptacja do nowych zadań |
| Zero-shot | 0 | Brak przykładów, uczenie przez przenoszenie wiedzy i opis klas |
Techniki promptowania i praktyki w few-shot/zero-shot learningu
Szczególną rolę w wykorzystaniu LLM (Large Language Models) odgrywają techniki promptowania. Wynik modelu może się diametralnie różnić w zależności od tego, jak sformułujemy instrukcję (prompt). Wyróżnia się kilka kluczowych strategii:
- Zero-shot prompting: model otrzymuje zadanie do wykonania bez żadnych przykładów — polega na precyzyjnym opisie celu (np. „Zaklasyfikuj tekst jako pozytywny, negatywny lub neutralny. Tekst: ‘Było dobrze’. Odpowiedź:”).
- Few-shot prompting: model otrzymuje kilka przykładowych wejść i wyjść, które pomagają wskazać pożądany format czy sposób myślenia (np. „Tekst: ‘To było kiepskie’. Sentiment: Negatywny. Tekst: ‘Bardzo się cieszę’. Sentiment: Pozytywny. Tekst: ‘Średnio mi się podobało’. Sentiment:”).
- Chain-of-thought prompting: polega na proszeniu modelu o wyjaśnienie swojego procesu rozumowania krok po kroku. Zamiast oczekiwać natychmiastowej odpowiedzi, model generuje rozbudowaną, logiczną ścieżkę prowadzącą do wyniku. Przykład: „Rozwiąż równanie 2x+3=11. Najpierw odejmij 3, potem podziel przez 2 itd.” Taki sposób działania ułatwia modelom rozwiązywanie zadań wymagających wieloetapowego myślenia.
- Tree-of-thought prompting: rozwinięcie CoT, gdzie model rozgałęzia rozumowanie na wiele ścieżek i analizuje każdą z nich niezależnie.
- Generated knowledge prompting: model najpierw generuje przydatne fakty lub wiedzę pomocniczą, a następnie rozwiązuje zadanie, bazując na tych informacjach.
- Directional-stimulus prompting: prompt zawiera wskazówki — słowa-klucze czy styl — które mają ukierunkować odpowiedź modelu.
In-context learning w praktyce
In-context learning to technika, w której model uczy się nowego zadania w locie, jedynie na bazie dostarczonych przykładów i szerszego kontekstu. Przykładowo, podając w promptcie kilka par pytanie–odpowiedź, model automatycznie dostosowuje się i generuje odpowiedzi w analogiczny sposób, bez modyfikowania parametrów — cała adaptacja odbywa się w trakcie pojedynczego wywołania (bez uczenia sieci na nowo). Funkcjonowanie in-context learningu jest niezbędne, szczególnie w zero- i few-shot learningu, gdyż pozwala efektywnie przekazywać wiedzę modelom językowym bez konieczności tradycyjnego, kosztownego retrainowania.
Praktyczne zastosowania i przykłady
Techniki uczenia bez danych mają szerokie spektrum użyteczności:
- Analiza tekstu (sentiment analysis, klasyfikacja tematów, ekstrakcja faktów) w językach czy dziedzinach niszowych lub nowych, gdzie nie istnieją duże zbiory treningowe.
- Medycyna – wykrywanie rzadkich schorzeń na podstawie bardzo skromnej liczby przypadków i obrazów medycznych.
- Zadania bezpieczeństwa – identyfikacja zagrożeń czy niepożądanych treści, gdy nie da się pozyskać przykładów wszystkich możliwych rodzajów ataków.
- Robotyka – szybka adaptacja robotów do nowych czynności pokazanych tylko kilka razy.
- Przetwarzanie języka naturalnego (NLP) – uczenie modeli rozpoznawania nowych języków czy stylów wypowiedzi.
- Rozpoznawanie obrazów – identyfikowanie nowych gatunków roślin, zwierząt lub obiektów przy minimalnej liczbie próbek.
„Few-shot i zero-shot learning pozwalają przełamać dotychczasowy paradygmat głębokiego uczenia, umożliwiając adaptację modeli do nowych wyzwań bez pogłębiania problemów związanych z kosztownym i czasochłonnym gromadzeniem danych.”
Wyzwania i najlepsze praktyki
- Dokładność promptu: Precyzyjna, jasno zdefiniowana instrukcja dla modelu jest kluczowa, zwłaszcza w zero-shot prompting, gdzie nawet niewielka nieprecyzyjność prowadzić może do niepożądanych rezultatów.
- Konstruowanie kontekstu: W few-shot learningu liczba i jakość pokazanych przykładów silnie wpływa na jakość odpowiedzi.
- Niezmienność parametrów modelu: In-context learning pozwala na szybkie eksperymentowanie bez czasochłonnego przeuczania modelu.
- Iteracyjne usprawnianie promptów: Efektywna praktyka to wielokrotne testowanie różnych wariantów promptów, ocena wyników i ich ciągłe udoskonalanie.
Podsumowanie
Few-shot i zero-shot learning to kluczowe technologie pozwalające wdrażać skuteczne systemy AI wszędzie tam, gdzie dostęp do danych jest ograniczony, a potencjalne zastosowania są bardzo szerokie: od medycyny i przemysłu, po edukację, cyberbezpieczeństwo, czy obsługę klienta. Ich rosnąca popularność wiąże się z szybkim rozwojem modeli językowych i uczeniem kontekstowym, dając możliwość elastycznego, skutecznego uczenia w nowych, nieznanych wcześniej domenach.
Źródła
- What Is Few-Shot Learning? (Coursera)
- What is Zero-Shot Learning? (Moveworks)
- What is Prompt Engineering? (AWS)
- What Is Few-Shot Learning? (IBM)
- What is Zero-Shot Learning? (H2O)
- Prompt engineering techniques: Top 5 for 2025 (K2View)
- A Step-by-step Guide to Few-Shot Learning (V7 Labs)
- What is Zero-shot Learning? Techniques & Implementation (Deepchecks)
- Prompt engineering (Wikipedia)
- What is Few-Shot Learning? | dida ML Basics
- What Is Zero-Shot Learning? (Coursera)
- Prompting Techniques
- A Summary of Approaches to Few-Shot Learning (arXiv)
- Zero-shot learning (Wikipedia)
- Prompt Engineering Techniques (IBM)
- Everything you need to know about Few-Shot Learning (DigitalOcean)
- What Is Zero-Shot Learning? (IBM)
- Prompt engineering techniques – Azure OpenAI
- Few-shot learning in Machine Learning (GeeksforGeeks)
- What Is Zero-Shot Learning? AI’s Game-Changing Technique (Grammarly)




