




Spis treści:
- Llama 4 – nowe modele
- NVIDIA z lepszym wsparciem dla Llamy
- Wybory programistów w AI przy programowaniu
Llama 4: Nowy wymiar efektywności w modelach językowych
Meta niedawno wprowadziła kolejną generację swojego flagowego modelu – Llama 4, która rewolucjonizuje podejście do architektury AI. Dwie kluczowe innowacje to mechanizm Mixture of Experts (MoE) oraz wczesna fuzja multimodalna, które znacząco poprawiają wydajność obliczeniową przy zachowaniu wysokiej jakości wyników.
Architektura nowej generacji
Sercem Llama 4 jest modularna struktura MoE, gdzie 109 miliardów parametrów w wariancie Scout dzieli się na 16 wyspecjalizowanych ekspertów. W praktyce oznacza to, że podczas generowania odpowiedzi aktywowane są jedynie 2-3 eksperci odpowiadające konkretnemu zadaniu, redukując rzeczywiste zużycie mocy obliczeniowej o 84% w porównaniu do tradycyjnych modeli monolitycznych.
| Parametr | Llama 4 Scout | Llama 4 Maverick |
|---|---|---|
| Całkowite parametry | 109B | 400B |
| Aktywne parametry | 17B | 17B |
| Liczba ekspertów | 16 | 128 |
Integracja z chmurą
Cloudflare udostępnia trzy główne ścieżki implementacji:
- Bezpośrednie wywołania REST API dla szybkich testów
- Pełna integracja z Workers AI dla aplikacji produkcyjnych
- Zaawansowane systemy RAG wykorzystujące okno kontekstowe 131k tokenów
“Wczesna fuzja multimodalna w Llama 4 eliminuje konieczność łańcuchowego łączenia specjalizowanych modeli, zapewniając spójność w przetwarzaniu tekstu i obrazów” – analiza techniczna Cloudflare
Zastosowania praktyczne
Developerzy mogą wykorzystać nowe możliwości do:
- Automatycznej analizy dokumentacji technicznej
- Generowania kodu z uwzględnieniem kontekstu projektu
- Tworzenia inteligentnych asystentów DevOps
NVIDIA przyspiesza operacje dla modeli Meta Llama 4 Scout i Maverick
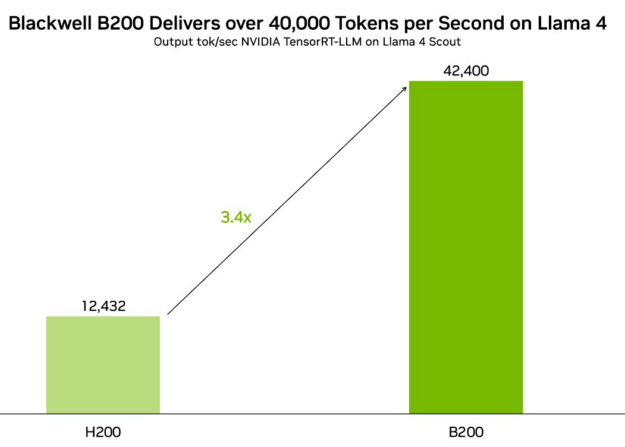
Najnowsza generacja popularnych modeli AI Llama od Meta zyskała znaczące przyspieszenie dzięki technologii NVIDIA. Modele Llama 4 Scout i Llama 4 Maverick, zoptymalizowane przy użyciu oprogramowania open-source NVIDIA, osiągają wydajność przekraczającą 40 000 tokenów na sekundę na procesorach graficznych NVIDIA Blackwell B200. Ta współpraca otwiera nowe możliwości dla aplikacji wykorzystujących zaawansowane modele językowe.
Źródło: NVIDIA
Architektura i możliwości modeli Llama 4
Modele Llama 4 wykorzystują architekturę Mixture of Experts (MoE), co czyni je natywnie multimodalnymi i wielojęzycznymi. Llama 4 Scout to model o 109 miliardach parametrów, z czego 17 miliardów jest aktywnych na token, skonfigurowany z 16 ekspertami i oknem kontekstowym o długości 10 milionów tokenów. Model został zoptymalizowany i skwantyzowany do int4 dla pojedynczego GPU NVIDIA H100, co umożliwia szeroki zakres zastosowań, takich jak wielodokumentowe podsumowania czy analizę rozległych baz kodu.
Z kolei Llama 4 Maverick to model o 400 miliardach parametrów, również z 17 miliardami aktywnych na token, ale ze 128 ekspertami i kontekstem o długości 1 miliona tokenów. Model ten wyróżnia się wysoką wydajnością w rozumieniu obrazów i tekstu, co czyni go idealnym do zastosowań multimodalnych.
Technologia NVIDIA TensorRT-LLM
NVIDIA zoptymalizowała oba modele Llama 4 przy użyciu biblioteki TensorRT-LLM, która jest otwartym narzędziem przyspieszającym wydajność wnioskowania LLM dla najnowszych modeli fundacyjnych na GPU NVIDIA. Deweloperzy mogą wykorzystać TensorRT Model Optimizer do przekształcania modeli bfloat16 z najnowszymi optymalizacjami algorytmicznymi i technikami kwantyzacji, przyspieszając wnioskowanie z wydajnością Blackwell FP4 Tensorcore bez wpływu na dokładność modelu.
Na GPU Blackwell B200, TensorRT-LLM zapewnia przepustowość ponad 40 000 tokenów na sekundę dla zoptymalizowanej przez NVIDIA wersji FP8 modelu Llama 4 Scout oraz ponad 30 000 tokenów na sekundę dla Llama 4 Maverick. Blackwell oferuje ogromne skoki wydajności dzięki innowacjom architektonicznym, w tym drugiej generacji Transformer Engine, piątej generacji NVLink oraz precyzji FP8, FP6 i FP4.
Praktyczne zastosowania i wdrożenia
Modele Llama 4 są dostępne jako mikrousługi NVIDIA NIM, co ułatwia ich wdrażanie na dowolnej infrastrukturze z akceleracją GPU, zapewniając elastyczność, prywatność danych i bezpieczeństwo klasy enterprise. NIM upraszcza wdrażanie poprzez wsparcie dla standardowych API branżowych, umożliwiając szybkie uruchomienie i bezproblemowe skalowanie w chmurach, centrach danych i środowiskach brzegowych.
Dostrajanie modeli Llama jest płynne dzięki NVIDIA NeMo, kompleksowemu frameworkowi do dostosowywania dużych modeli językowych (LLM) do danych przedsiębiorstwa. Proces rozpoczyna się od przygotowania wysokiej jakości zestawów danych za pomocą NeMo Curator, a następnie wykorzystuje NeMo do efektywnego dostrajania modeli z technikami takimi jak LoRA, PEFT i pełne dostrajanie parametrów.Źródła
Młodzi programiści napędzają rewolucję open-source’ową w AI
Dynamiczny rozwój efektywnych kosztowo modeli AI opartych na otwartym kodzie źródłowym intensyfikuje dyskusję między zwolennikami rozwiązań open-source a własnościowych. Społeczności open-source były fundamentalne dla rozwoju internetu i platform takich jak Stack Overflow. Nawet rządy na całym świecie rozważają regulacje oraz deklarują znaczące inwestycje w kierunku uczynienia AI dobrem publicznym.
Źródło: stack overflow
Pokoleniowy podział w adaptacji open-source AI
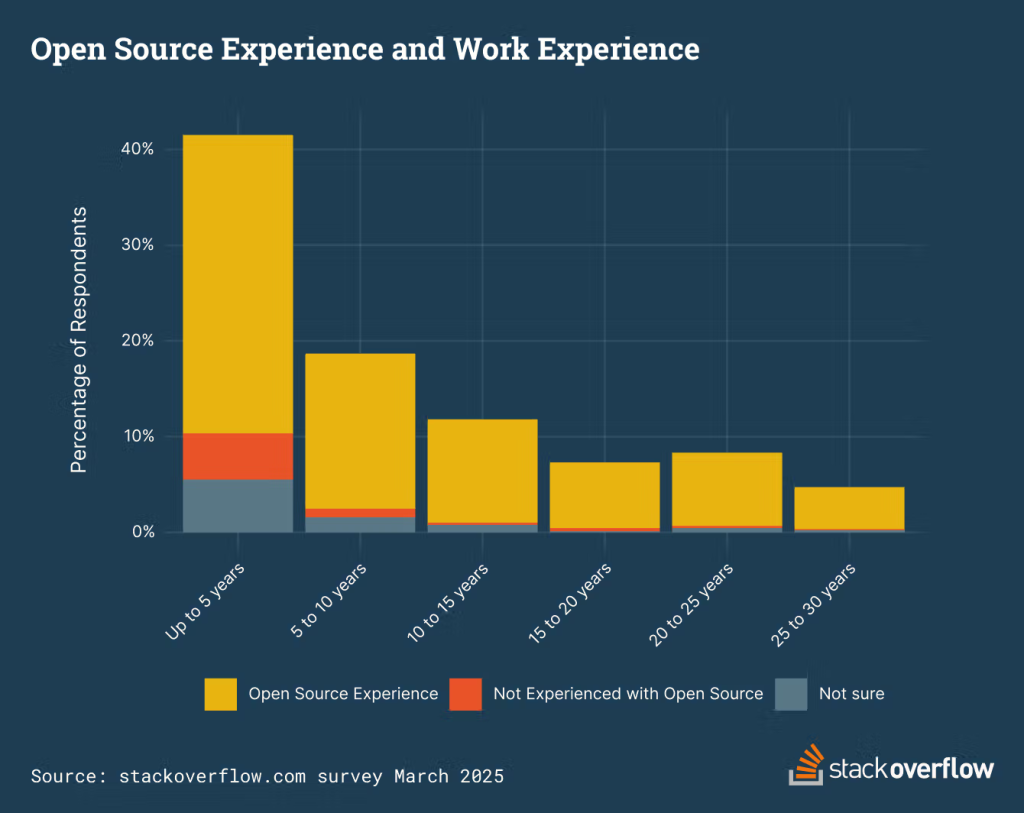
Według badania przeprowadzonego przez Stack Overflow w marcu 2025 roku, zdecydowana większość (82%) deweloperów ma doświadczenie z technologiami open-source. Analiza trendów Q&A platformy wskazuje na silne wsparcie dla technologii open-source – w ciągu ostatniego roku 40% z 1000 najpopularniejszych tagów związanych było z oprogramowaniem o otwartym kodzie źródłowym.
Interesujący jest fakt, że programiści na początku kariery wykazują najmniejsze doświadczenie z technologiami open-source – 12% respondentów z mniej niż 5-letnim stażem nie korzystało wcześniej z tego typu rozwiązań. Jednocześnie, młodsi deweloperzy (20-34 lata) wykazują większe zainteresowanie chatbotami AI niż ich starsi koledzy.
Źródło: stack overflow
Kwestia zaufania: open-source kontra rozwiązania własnościowe
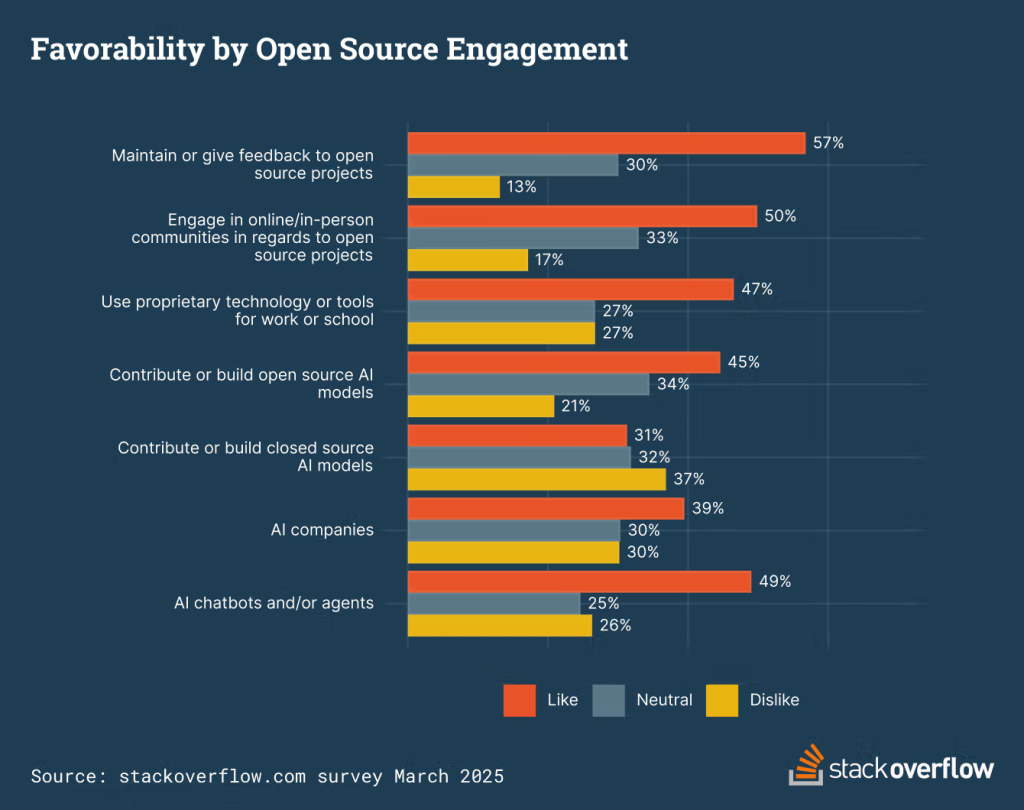
Zaufanie do AI open-source jest znacząco wyższe w porównaniu do własnościowych odpowiedników. Większość ankietowanych ufa AI open-source w projektach osobistych lub edukacyjnych (66%) oraz w pracy programistycznej (61%), podczas gdy dla AI własnościowego wartości te wynoszą odpowiednio 52% i 47%.
Modele DeepSeek R1, DeepSeek V3 oraz Meta Llama 70B cieszą się największą rozpoznawalnością wśród open-source’owych LLM, konkurując z własnościowymi modelami GPT-4o i Claude 3.5/3.7 Sonnet.
Praktyczne implikacje dla branży
AI open-source to nie tylko projekt społeczności – to prawdziwa szansa biznesowa. Firmy mogą inwestować w projekty open-source poprzez świadczenie płatnych usług utrzymania i wsparcia, rozwijanie kluczowych funkcji własnościowych przy zachowaniu otwartego rdzenia, oferowanie usług zarządzanych, podwójne licencjonowanie oraz przyjmowanie darowizn na rozwój.
Kwestią do rozwiązania pozostają wyzwania związane z bezpieczeństwem (44% ankietowanych uważa AI open-source za ryzyko) oraz poprawa odkrywalności projektów i zbiorów danych. Ułatwienie współdzielenia wiedzy poprzez społeczności online będzie kluczowe dla wzmocnienia obecnych i przyszłych pokoleń programistów AI.


