Spis treści
- Khoj – Twój osobisty asystent AI typu open source
- Inteligentna selekcja czujników w systemach brzegowych AI – nowe podejście semantyczne
- Trening i dostrajanie modeli rekategoryzacji z wykorzystaniem Sentence Transformers v4
Khoj – Twój osobisty asystent AI typu open source
Khoj to otwartoźródłowa aplikacja AI zaprojektowana jako “drugi mózg” użytkownika, która pomaga rozszerzać nasze możliwości poznawcze. Projekt oferuje elastyczne rozwiązanie, skalujące się od lokalnej aplikacji działającej na własnym urządzeniu aż po rozwiązanie chmurowe na poziomie przedsiębiorstwa.
Kluczowe możliwości techniczne
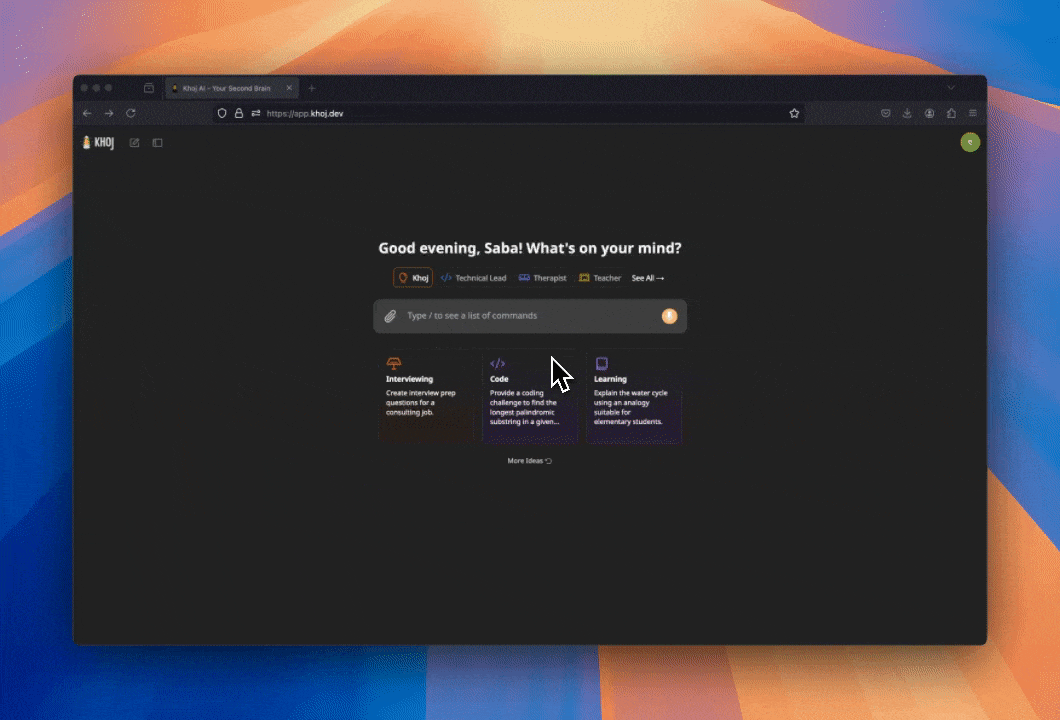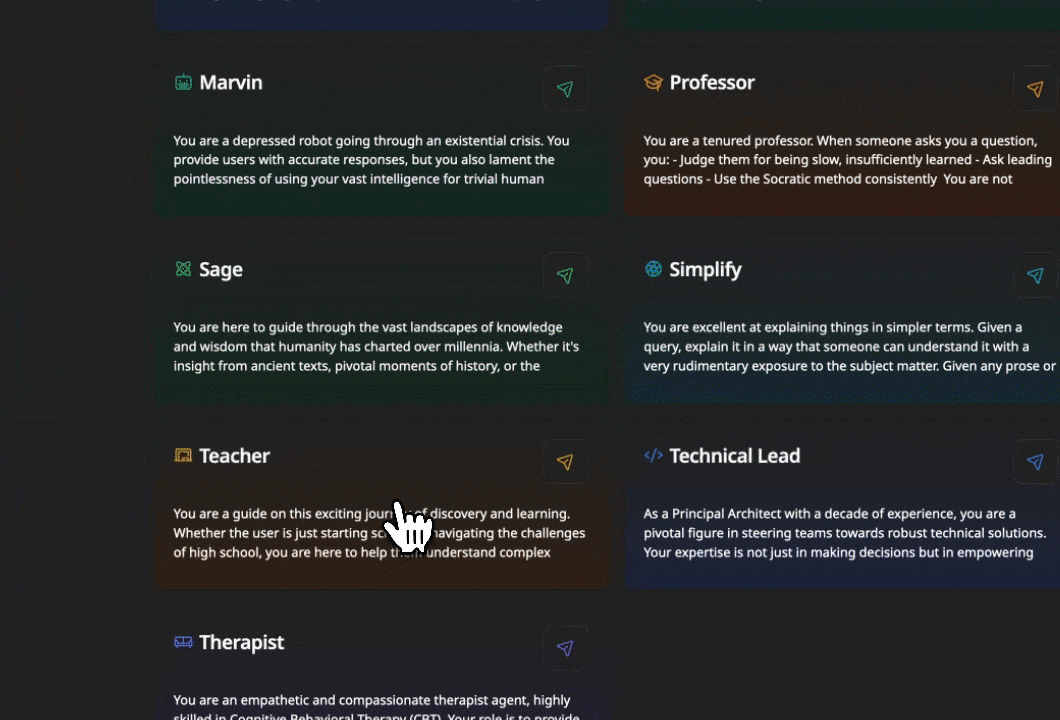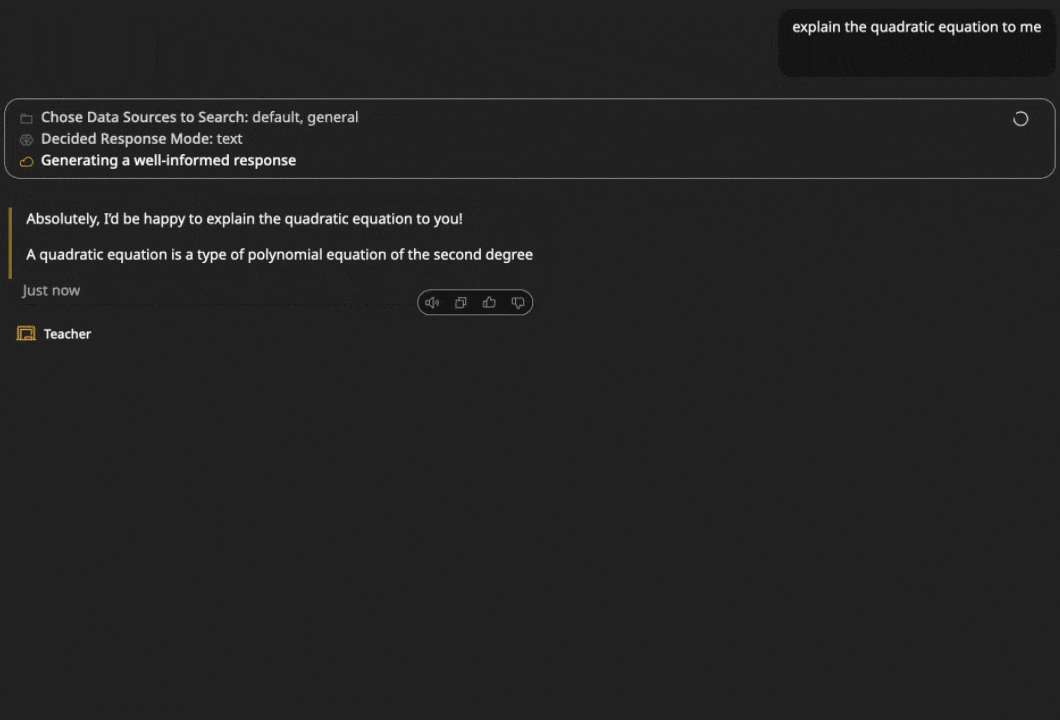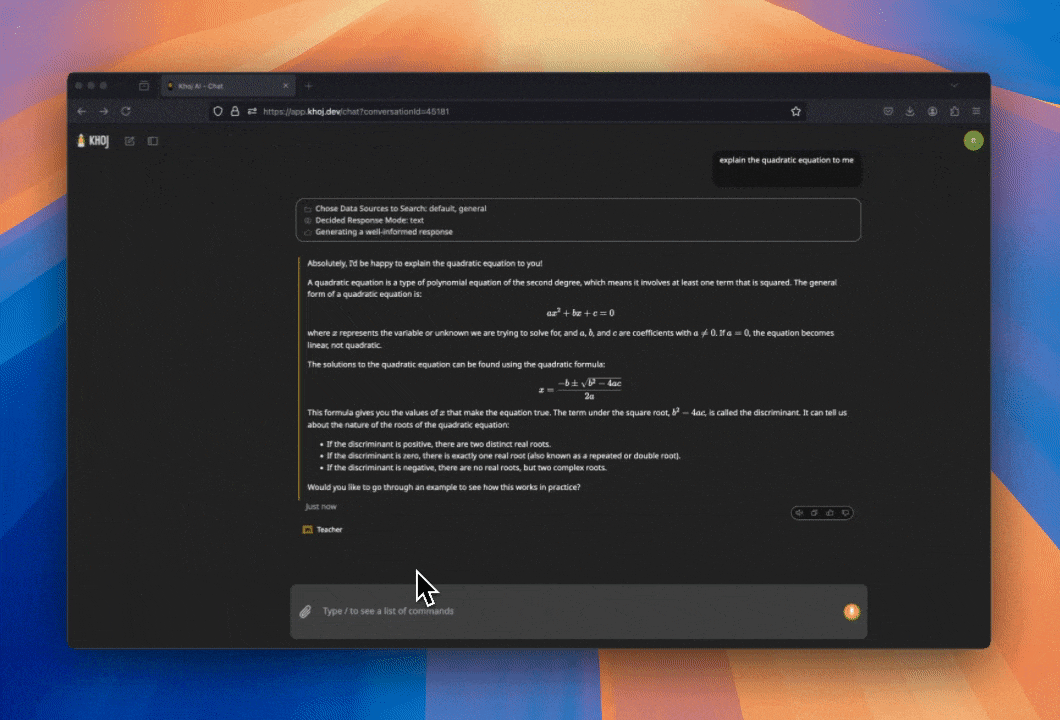
Khoj umożliwia prowadzenie konwersacji z różnorodnymi modelami językowymi, zarówno lokalnymi jak i dostępnymi online. Obsługuje modele takie jak llama3, qwen, gemma, mistral, a także GPT, Claude i Gemini. Aplikacja potrafi analizować i przetwarzać dane z internetu oraz z dokumentów użytkownika, w tym plików obrazowych, PDF, markdown, org-mode, dokumentów Word oraz Notion.
Dostęp do Khoj możliwy jest z poziomu przeglądarki, wtyczki do Obsidian, Emacs, aplikacji desktopowej, telefonu, a nawet poprzez WhatsApp. Użytkownicy mogą tworzyć własne agenty z dostosowaną wiedzą, osobowością i narzędziami, przeznaczone do konkretnych zadań.
Technologia i architektura
Pod maską Khoj wykorzystuje zaawansowane wyszukiwanie semantyczne, umożliwiające szybkie znajdowanie odpowiednich dokumentów i notatek. System używa modeli bi-encoder do tworzenia wektorów znaczeniowych dokumentów i zapytań, co pozwala na znalezienie najbardziej trafnych fragmentów. Do przechowywania tych wektorów wykorzystywana jest baza danych PostgreSQL z rozszerzeniem pgvector.
Jak wykorzystać Khoj
- Automatyzacja powtarzalnych badań poprzez zaplanowane zadania
- Wyszukiwanie dokumentów przy użyciu zapytań w języku naturalnym
- Tworzenie niestandardowych agentów do specjalistycznych zadań
- Generowanie obrazów i interakcja głosowa
- Wykonywanie prostego kodu Python do analizy danych
Khoj jest w pełni otwartoźródłowy i może być hostowany na własnym serwerze, co zapewnia pełną kontrolę nad danymi. Dla osób preferujących rozwiązania chmurowe, dostępna jest wersja online pod adresem app.khoj.dev.
Inteligentna selekcja czujników w systemach brzegowych AI – nowe podejście semantyczne
Rozwój sieci szóstej generacji (6G) wprowadza nowe wyzwania w obszarze przetwarzania danych z wielu czujników na brzegu sieci. Systemy wykrywania wzmocnione sztuczną inteligencją brzegową (Edge-AI) muszą radzić sobie z ogromną ilością danych sensorycznych. W najnowszym badaniu naukowcy proponują przełomowe podejście do tego problemu, wykorzystując semantyczną istotność jako kryterium wyboru czujników.
Czym jest ISEA i dlaczego to ważne?
Integrated Sensing and Edge AI (ISEA) to nowy paradygmat łączący funkcje wykrywania i sztucznej inteligencji brzegowej w sieciach 6G. Umożliwia przetwarzanie i analizę danych sensorycznych w czasie rzeczywistym bezpośrednio na brzegu sieci, bez konieczności przesyłania wszystkich danych do chmury. Problem pojawia się gdy liczba czujników i wymiarowość ich danych przekracza przepustowość dostępnych kanałów komunikacyjnych, co prowadzi do wąskiego gardła.
Dotychczasowe rozwiązania nie uwzględniały w odpowiednim stopniu istotności semantycznej – czyli poziomu powiązania obserwacji czujnika z końcowym zadaniem. Praca przedstawiona w artykule wprowadza strukturę, która świadomie uwzględnia tę istotność przy wyborze czujników, co pozwala na optymalizację wydajności zadania end-to-end.
Kluczowe innowacje technologiczne
Autorzy sformułowali problem selekcji czujników jako program całkowitoliczbowy i zaproponowali ścisłe przybliżenie funkcji celu. Co ciekawe, optymalne rozwiązanie wykazuje strukturę opartą na priorytetach, która szereguje czujniki na podstawie wskaźnika łączącego oceny istotności i stany kanału komunikacyjnego, a następnie wybiera czujniki o najwyższej randze.
Opracowane algorytmy o niskiej złożoności obliczeniowej pozwalają na określenie optymalnej liczby wybranych czujników i istotnych cech. Ma to kluczowe znaczenie dla systemów pracujących w czasie rzeczywistym, gdzie opóźnienia w przetwarzaniu danych mogą mieć krytyczne konsekwencje.
Praktyczne zastosowania
Zaproponowane podejście może znaleźć zastosowanie w wielu obszarach wykorzystujących rozproszone systemy czujników, takich jak:
- Inteligentne miasta monitorujące ruch, jakość powietrza i infrastrukturę
- Aplikacje przemysłowe Przemysłu 4.0 z licznymi czujnikami monitorującymi procesy produkcyjne
- Systemy autonomicznych pojazdów przetwarzające dane z wielu sensorów
- Rozszerzone sieci monitoringu zdrowia z noszonymi urządzeniami medycznymi
Testy przeprowadzone zarówno na danych syntetycznych, jak i rzeczywistych, wykazały znaczącą poprawę dokładności w porównaniu do istniejących rozwiązań. Oznacza to, że przy tej samej przepustowości łącza można uzyskać lepsze wyniki końcowe zadania lub zredukować wymagania komunikacyjne bez pogorszenia jakości.
Trening i dostrajanie modeli rekategoryzacji z wykorzystaniem Sentence Transformers v4
Modele rekategoryzacji (reranker models) odgrywają kluczową rolę w nowoczesnych systemach wyszukiwania informacji. Przetwarzają one pary tekstów wspólnie przez sieć neuronową, co pozwala na dokładniejszą ocenę istotności dokumentu względem zapytania. Biblioteka Sentence Transformers w wersji 4 wprowadza nowe rozwiązania ułatwiające trening takich modeli.
Czym są modele rekategoryzacji?
Modele rekategoryzacji, często implementowane jako Cross Encodery, służą do oceny istotności między parami tekstów (np. zapytanie i dokument). W przeciwieństwie do modeli embeddingowych (bi-encoderów), które przetwarzają każdy tekst oddzielnie, Cross Encodery analizują pary tekstów razem, pozwalając na wzajemną uwagę między nimi. Dzięki temu osiągają wyższą jakość oceny istotności, ale kosztem szybkości przetwarzania.
Te modele są najczęściej używane w dwuetapowym procesie wyszukiwania: najpierw szybki model embeddingowy wybiera potencjalnie istotne dokumenty, a następnie dokładniejszy model rekategoryzacji precyzyjnie szereguje te wyniki.
Komponenty treningu modeli rekategoryzacji
Trening modeli rekategoryzacji w Sentence Transformers v4 obejmuje kilka kluczowych elementów:
- Zbiory danych – możliwość wykorzystania danych z Hugging Face Hub lub lokalnych danych
- Funkcje straty – dostępnych jest ponad 10 różnych funkcji dostosowanych do konkretnych zadań
- Parametry treningu – pozwalające na optymalizację procesu uczenia
- Ewaluatory – narzędzia do oceny modelu przed, w trakcie i po treningu
- Trener – klasa integrująca wszystkie komponenty
Praktyczne zastosowania
Sentence Transformers v4 wprowadza istotne usprawnienia w obszarze treningu modeli rekategoryzacji, w tym:
- Wsparcie dla treningu wieloGPU (Data Parallelism i Distributed Data Parallelism)
- Wsparcie dla treningu w precyzji BF16
- Automatyczne generowanie kart modeli (model cards)
- Ulepszony system callbacków
- Możliwość wydobywania trudnych przykładów negatywnych do treningu
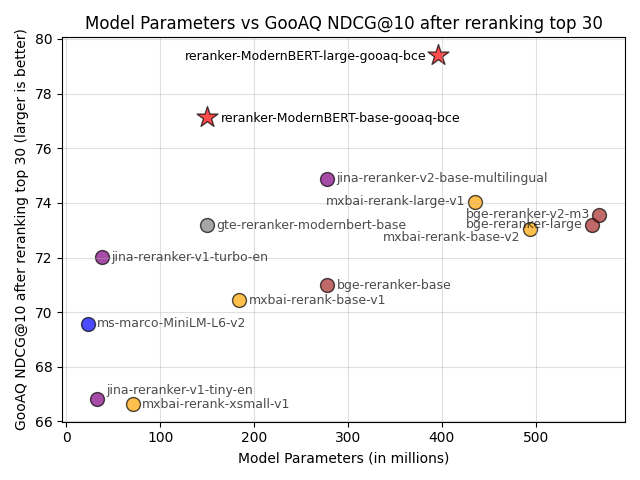
Co ciekawe, badania pokazują, że dostrojenie nawet niewielkiego modelu rekategoryzacji do konkretnej domeny może znacząco przewyższyć wydajność ogólnych modeli, nawet tych znacznie większych. Na przykład, model tomaarsen/reranker-ModernBERT-base-gooaq-bce (150M parametrów) przewyższył 13 popularnych modeli rekategoryzacji na zestawie testowym GooAQ, osiągając wynik NDCG@10 wynoszący 77.14.