




Przedstawiony kod implementuje kompleksowe rozwiązanie do automatycznej transkrypcji plików multimedialnych z generacją napisów SRT, wykorzystujące najnowsze osiągnięcia w dziedzinie rozpoznawania mowy. System integruje model Whisper Turbo firmy OpenAI z infrastrukturą przetwarzania multimedialnego, oferując wydajną konwersję mowy na tekst z dokładnym oznaczeniem czasowym.
Wymagania techniczne
System wymaga następujących komponentów:
| Komponent | Wersja | Cel |
|---|---|---|
| Python | 3.8+ | Środowisko wykonawcze |
| Whisper | 2024.10+ | Model transkrypcji |
| FFmpeg | 7.1+ | Przetwarzanie multimediów |
| PyTorch | 2.3+ | Inferencja modeli ML |
Instrukcja implementacji
Krok 1: Przygotowanie środowiska
Instalacja potrzebnych zależności może się różnić np. instalacja ffmpeg dla ubuntu
sudo apt update && sudo apt install -y ffmpeg python3-pip Gdzie dla systemów Windows wygląda to inaczej, musimy pobrać ffmpeg z oficjalnej strony projektu.

Następnie pobrane archiwum należy wypakować w wybrane przez siebie miejsce na dysku i dodać ścieżkę ffmpeg do pliku exe (folder ffmpeg/bin/) do zmiennej środowiskowej a zrobimy to korzystając z wyszukiwarki
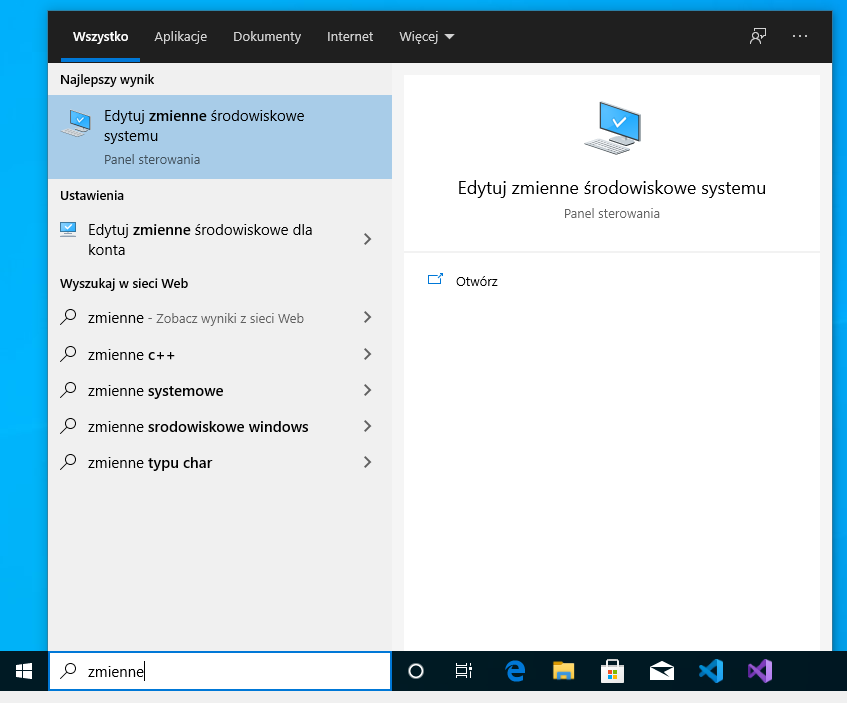
a następnie dodając ścieżkę do folderu w PATH
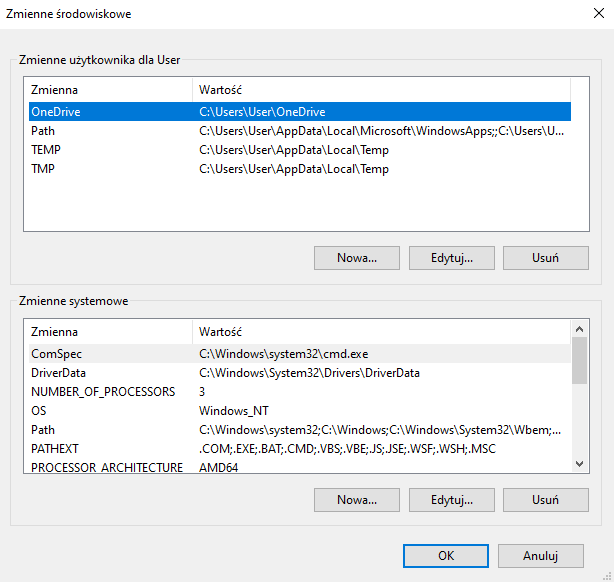
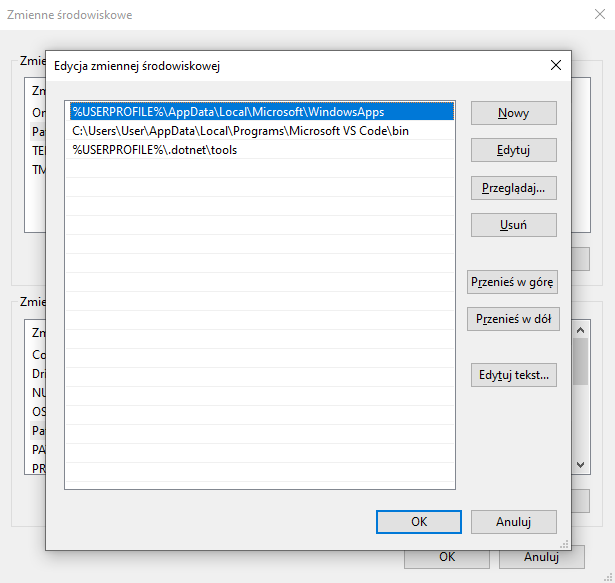
Krok 2: Instalacja pakietów Python
pip install openai-whisperKrok 3: Implementacja.
import os
import platform
import subprocess
import sys
import whisper
import torch
def check_ffmpeg_installed():
try:
subprocess.run(["ffmpeg", "-version"], check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
return True
except (subprocess.CalledProcessError, FileNotFoundError):
return False
def get_os_specific_instructions():
current_os = platform.system()
instructions = {
"Darwin": "\n\033[94mBrew install command:\nbrew install ffmpeg\033[0m",
"Windows": "\n\033[94mChocolatey install command:\nchoco install ffmpeg\n\nScoop install command:\nscoop install ffmpeg\033[0m",
"Linux": "\n\033[94mAPT install command:\nsudo apt install ffmpeg\033[0m"
}
return instructions.get(current_os, "Please install FFmpeg for your operating system")
def format_timestamp(seconds):
hrs = int(seconds // 3600)
mins = int((seconds % 3600) // 60)
secs = int(seconds % 60)
msecs = int((seconds - int(seconds)) * 1000)
return f"{hrs:02}:{mins:02}:{secs:02},{msecs:03}"
def validate_file_path(file_path):
if not os.path.isfile(file_path):
raise FileNotFoundError(f"Input file not found: {file_path}")
if not file_path.lower().endswith(('.mp4', '.avi', '.mov', '.mkv', '.mp3', '.wav', '.flac')):
raise ValueError("Unsupported file format. Please provide a video or audio file")
def optimize_system_settings():
if torch.cuda.is_available():
torch.backends.cudnn.benchmark = True
torch.set_num_threads(4)
def preprocess_audio(file_path):
temp_file = "temp_audio.wav"
cmd = [
"ffmpeg",
"-y", "-i", file_path,
"-ac", "1", "-ar", "16000",
"-c:a", "pcm_s16le",
"-hide_banner", "-loglevel", "error",
temp_file
]
subprocess.run(cmd, check=True)
return temp_file
def main():
try:
# Detect operating system
current_os = platform.system()
print(f"\033[1mDetected operating system: {current_os}\033[0m")
# Check FFmpeg installation
if not check_ffmpeg_installed():
print("\033[91mFFmpeg is not installed or not in system PATH\033[0m")
print(get_os_specific_instructions())
return
# Optimize system settings
optimize_system_settings()
# Load Whisper Turbo model
print("\n\033[93mLoading Whisper Turbo model... (Initial download may take several minutes)\033[0m")
model = whisper.load_model("turbo")
# Get input file path
file_path = input("\n\033[1mEnter path to media file: \033[0m").strip()
validate_file_path(file_path)
# Preprocess audio
preprocessed_file_path = preprocess_audio(file_path)
# Transcribe content
print("\n\033[96mStarting transcription...\033[0m")
result = model.transcribe(preprocessed_file_path, task='transcribe')
# Save results as SRT subtitles
base_name = os.path.splitext(os.path.basename(file_path))[0]
output_file = f"{base_name}.srt"
with open(output_file, "w", encoding="utf-8") as f:
for i, segment in enumerate(result.get("segments", []), start=1):
start = format_timestamp(segment["start"])
end = format_timestamp(segment["end"])
text = segment["text"].strip()
f.write(f"{i}\n{start} --> {end}\n{text}\n\n")
print(f"\n\033[1;92mTranscription complete! Saved to:\033[0m {output_file}")
print(f"\033[95mProcessing time: {result['segments'][-1]['end']:.1f}s\033[0m")
except Exception as e:
print(f"\n\033[91mError: {str(e)}\033[0m")
sys.exit(1)
if __name__ == "__main__":
main()Implementacja zawiera następujące funkcje:
check_ffmpeg_installed()– która sprawdzaczy ffmpeg jest zainstalowaneget_os_specific_instructions()– sprawdza na jakim systemie jest uruchomione(Windows,Linux,MacOS)format_timestamp()– tworzący timestampy dla formatu srtvalidate_file_path()– sprawdzający format plikumain()– realizujący całą logikę projektu.preprocess_audio()– przygotowywujący audio pod transkrypcjeoptimize_system_settings()– wybierający najlepszą opcje dla wykrytej konfiguracji
Uruchomienie i działanie
W terminalu uruchamiamy poprzez komendę
python transcribe_whisper.pyNastąpi wtedy pobranie modelu whisper turbo i po poprawnym pobraniu zostanie wyświetlony komunikat o podaniu ścieżki do filmu gdzie po tym nastąpi transkrypcja.

prędkość transkrypcji jest zależna od sprzętu i materiału oraz języka w materiale źródłowym, jeśli chcesz przeczytać więcej na ten temat zapraszam do wątku na githubie.
Repozytorium
Implementacja jest dostępna też na githubie pod adresem.
Dodatkowo jest tam też implementacja pod sam dźwięk.
Źródło:


