




Spis treści
- Techniczne podstawy systemu Whisper
- Warianty modelu i konfiguracje sprzętowe
- Implementacja techniczna i integracja z YouTube
- Praktyczne zastosowania i optymalizacja wydajności
- Jak zacząć korzystać?
Projekt whisper-youtube stanowi praktyczną implementację automatycznego rozpoznawania mowy, wykorzystującą model Whisper OpenAI do transkrypcji filmów z YouTube. Rozwiązanie zostało zaprojektowane jako notebook Jupyter działający w środowisku Google Colab, oferując użytkownikom prostą metodę konwersji treści audio na tekst.
Techniczne podstawy systemu Whisper
Model Whisper reprezentuje przełomowe podejście do rozpoznawania mowy, wykorzystując architekturę transformer encoder-decoder. System został wytrenowany na obszernym zestawie danych obejmującym 680 tysięcy godzin nagrań audio z odpowiadającymi im transkrypcjami. Kluczową przewagą Whisper jest jego zdolność do obsługi 98 języków oraz wykonywania zadań transkrypcji i tłumaczenia bez konieczności dodatkowego treningu.
Architektura modelu opiera się na dwuetapowym procesie przetwarzania. Enkoder analizuje sygnały audio przekształcone w spektrogramy log-mel, tworząc reprezentacje wektorowe zawierające kontekst mowy. Dekoder wykorzystuje te reprezentacje do generowania tekstu, uwzględniając poprzednie tokeny oraz całościowy kontekst audio. System automatycznie rozpoznaje interpunkcję i różne style mówienia, osiągając poziom błędów WER na poziomie około 8%.
Warianty modelu i konfiguracje sprzętowe
Projekt oferuje wybór spośród pięciu podstawowych wariantów modelu Whisper, różniących się rozmiarem i wymaganiami obliczeniowymi. Model tiny z 39 milionami parametrów wymaga około 1 GB pamięci VRAM i pracuje 32 razy szybciej od największego modelu. Base (74M parametrów) oferuje kompromis między szybkością a dokładnością, działając 16 razy szybciej przy podobnych wymaganiach sprzętowych.
| Model | Parametry | Wymagania VRAM | Względna szybkość |
|---|---|---|---|
| tiny | 39M | ~1GB | 32x |
| base | 74M | ~1GB | 16x |
| small | 244M | ~2GB | 6x |
| medium | 769M | ~5GB | 2x |
| large | 1550M | ~10GB | 1x |
Środowisko Google Colab zapewnia dostęp do różnych konfiguracji GPU, wpływających bezpośrednio na wydajność transkrypcji. Tesla T4 (8.1 teraFLOPS) dostępne w wersji bezpłatnej, P100 (10.6 teraFLOPS) oraz rzadziej dostępne V100 (15.7 teraFLOPS) w ramach Colab Pro. Wybór GPU determinuje czas przetwarzania – większa moc obliczeniowa pozwala na wykorzystanie większych modeli z wyższą dokładnością.
Implementacja techniczna i integracja z YouTube
System wykorzystuje bibliotekę pytube do pobierania filmów YouTube oraz ffmpeg-python do przetwarzania audio. Proces rozpoczyna się od ekstrakcji ścieżki dźwiękowej z filmu, następnie audio jest dzielone na 30-sekundowe segmenty i konwertowane do spektrogramów log-mel. Ta segmentacja umożliwia efektywne przetwarzanie długich nagrań bez przekraczania limitów pamięci.
Implementacja obsługuje różne formaty wyjściowe transkrypcji, w tym VTT (Video Text Tracks) z precyzyjnymi znacznikami czasowymi. Funkcjonalność automatycznego zapisu do Google Drive eliminuje konieczność ręcznego zarządzania plikami wynikowymi. System generuje pliki zawierające zarówno transkrypcje jak i opcjonalnie pliki audio w formacie MP3.
Praktyczne zastosowania i optymalizacja wydajności
Rozwiązanie znajduje zastosowanie w szerokim spektrum scenariuszy użytkowych. Edukatorzy mogą wykorzystywać je do tworzenia automatycznych napisów dla materiałów szkoleniowych, zwiększając dostępność treści dla osób z wadami słuchu. Content creatorzy zyskują możliwość szybkiego generowania transkrypcji do celów SEO oraz tworzenia artykułów na podstawie treści video.
W kontekście badań naukowych, system umożliwia analizę treści wywiadów i prezentacji. Dziennikarze mogą automatyzować proces transkrypcji wywiadów, znacznie przyspieszając workflow redakcyjny. Dla organizacji prowadzących szkolenia online, automatyczna transkrypcja ułatwia tworzenie materiałów tekstowych i umożliwia wyszukiwanie w treści.
Optymalizacja wydajności wymaga dostrojenia parametrów do specyfiki audio. Dla nagrań wysokiej jakości z jednym mówiącym wystarczające mogą być mniejsze modele, podczas gdy treści wielojęzyczne lub nagrania niskiej jakości wymagają modelu large. System automatycznie wykrywa język, ale specyfikacja może poprawić dokładność wyników.
Jak zacząć korzystać?
Należy udać się na repozytorium użytkownika ArturFDLR/whisper-youtube, następnie w opisie repozytorium kliknąć w notebook.

Następnie otworzy nam się notatnik google colab.
Poszczególne sekcje uruchamiamy przez naciśnięcie przycisku play.
W notatniku mamy następujące sekcje:
- Check GPU type – sprawdza jakie GPU mamy dostępne(czy korzystamy z płatnego planu czy darmowego).
- Install libraries – instaluje niezbędne biblioteki pythona do działania.
- Optional: Save data in Google Drive – zapisuje plik z napisami w google drive.
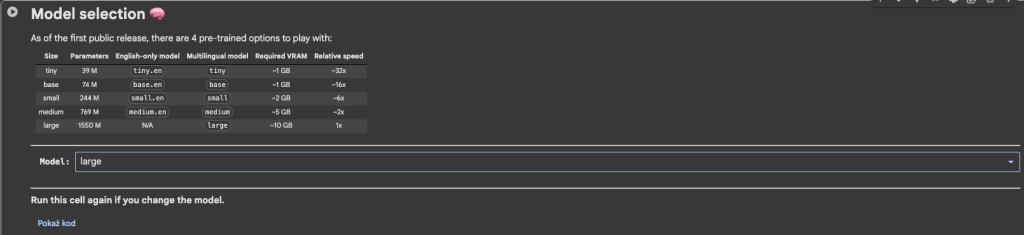
- Model selection – wybór modelu.
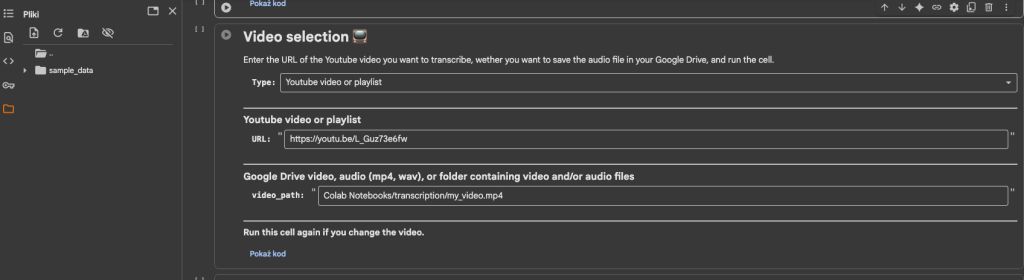
- Video selection – wybór wideo, można podać link youtube albo plik na dysku google(wymagany punkt opcjonalny)
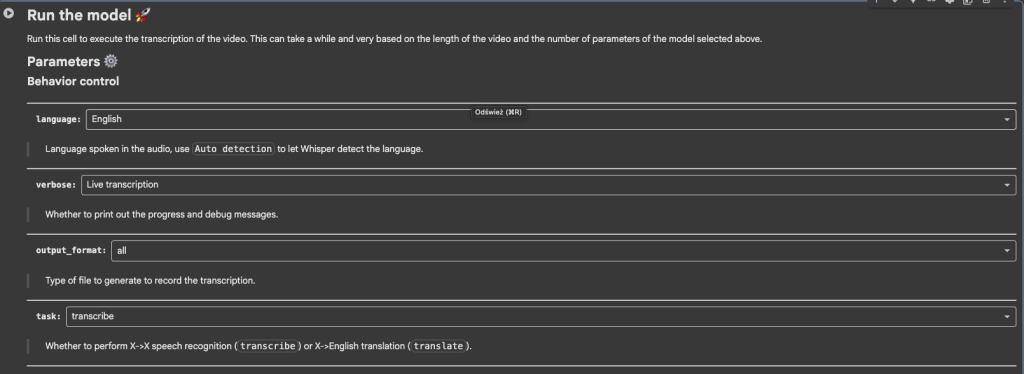
- Run the model – uruchomienie modelu.
Gdy już wiemy co robią poszczególne sekcje możemy uruchomić transkrypcje, Check GPU type oraz Install libraries uruchamiamy od razu, o poprawności wykonania poinformuje nas potwierdzenie obok przycisku.
W Model selection wybieramy large
W Video selection wprowadzamy namiary na nasze wideo, w przypadku treści z youtube podajemy adres.
W przypadku własnego wideo to najpierw przesyłamy je na dysk google i łączymy z punktem opcjonalnym (wyświetli się okno logowania do google drive).
I z poziomu plików (panel po lewej) znajdujemy nasze wideo i co istotne prawym przyciskiem myszy wybieramy opcję skopiuj ścieżkę i wklejamy w video path i zmieniamy type na google drive
W ostatnim kroku Run the model, mamy parę opcji do wybrania w tym język który ustawiamy na taki w którym jest materiał źródłowy i output format w zależności od potrzeb (najczęstszy format dla napisów to .srt).
Po tym możemy uruchomić i czekać na zakończenie.
Pliki pojawią się albo w google drive (jeśli wybrałeś opcje by tam zapisać) lub w plikach notatnika które znajdziesz po prawej stronie.
Źródła
- What is OpenAI Whisper, and How to Make the Most of It
- Advanced Techniques for YouTube Video to Word Transcription
- Google CoLab Enterprise at UMD – IT Support
- What is OpenAI Whisper?
- Which Whisper Model Should I Choose?
- OpenAI’s Whisper speech model – an overview
- How to Use FFMpeg in Python (with Examples)
- Train Machine Learning Models on Colab GPU
- Auto-Sync Meeting Data to Google Drive with Fireflies

