




W erze dynamicznego rozwoju sztucznej inteligencji, możliwość lokalnego uruchamiania dużych modeli językowych (LLM) staje się kluczową kompetencją dla developerów i entuzjastów technologii. Ollama jako przełomowe narzędzie open source, oferujące bezprecedensową prostotę w instalacji i konfiguracji modeli takich jak Llama 3 czy Mistral. W przeciwieństwie do chmurowych rozwiązań, ta platforma zapewnia pełną kontrolę nad danymi i procesami przetwarzania, eliminując jednocześnie koszty subskrypcji oraz co najważniejsze działając lokalnie pozwala działać bez dostępu do internetu zapewniając prywatność.
Architektura Ollamy w pigułce
Rdzeń systemu opiera się na lekkim środowisku wykonawczym obsługującym format GGUF, optymalizujący wykorzystanie zasobów sprzętowych. Domyślna konfiguracja wykorzystuje serwer lokalny na porcie 11434, udostępniający REST API do integracji z zewnętrznymi aplikacjami. Mechanizm zarządzania modelami through semantic versioning pozwala na równoległe utrzymywanie różnych wersji tej samej architektury neuronalnej.
Proces instalacji krok po kroku
Dla systemów z rodziny Debian/Ubuntu instalcja sprowadza się do wykonania w terminalu:
curl -fsSL https://ollama.com/install.sh | sh Użytkownicy Windows pobierają instalator MSI ze strony projektu, podczas gdy na macOS proces obejmuje instalację przez Homebrew. Weryfikację poprawnej instalacji przeprowadza się komendą ollama --version, oczekując odpowiedzi w formacie semantycznego versioningu.
Można ją pobrać stąd.
| System | Ścieżka modeli | Port domyślny |
|---|---|---|
| Linux | /usr/share/ollama/models | 11434 |
| Windows | C:\Users\%USERNAME%\.ollama\models | 11434 |
Podstawowe operacje modelowe
Implementacja nowego modelu rozpoczyna się od komendy ollama pull nazwa_modelu, gdzie nazwa odpowiada repozytorium w bibliotece Ollamy. Przykładowo, dla Llama 3 8B użyjemy:ollama run llama3:8b
ollama run llama3:8b Zaawansowane zarządzanie obejmuje funkcje takie jak:
- Wersjonowanie modeli przez dodanie sufiksu :wersja
- Dynamiczne przełączanie kontekstów z użyciem flagi –model
- Eksport/import modeli w formacie binarnym
Konfiguracja przez Modelfile
Pliki konfiguracyjne w formacie Modelfile pozwalają na precyzyjne dostrojenie parametrów wykonawczych. Przykładowa deklaracja dla modelu specjalizowanego wygląda następująco:
FROM llama3:8b PARAMETER num_ctx 4096 SYSTEM """ Jesteś ekspertem ds. prawa cywilnego specjalizującym się w kodeksie rodzinnym. Odpowiadaj precyzyjnie, cytując konkretne artykuły ustaw. """ Integracja z ekosystemem developerskim
Ollama eksponuje kompletne REST API dokumentowane przez Swagger UI dostępne pod /docs. Przykładowe zapytanie przez cURL:
curl -X POST http://localhost:11434/api/generate -d '{ "model": "llama3:8b", "prompt": "Wyjaśnij teorię względności w trzech zdaniach", "stream": false }' Dla środowisk graficznych rekomendowana jest integracja z Open WebUI – frameworkiem Reactowym oferującym interfejs jak ChatGPT.
Wykorzystywanie w skryptach pythona.
Nie jesteśmy ograniczeni jedynie do porozumiewania się z modelami poprzez zewnętrzne nakładki czy też terminal/cmd, można to zrobić za pomocą poniższego kodu:
import ollama
response = ollama.chat(
model='deepseek-r1:8b',
messages=[{
'role': 'user',
'content': "Prompt użytkownika"
}]
)
print(response['message']['content'])Gdzie model to wskazanie dokładnej nazwy z komendy
ollama lista w messages rola oraz prompt, to pole może się różnić w zależności od modelu, niektóre jak np. llama3.2-vision obsługują pliki i potrafią być obsługiwane.
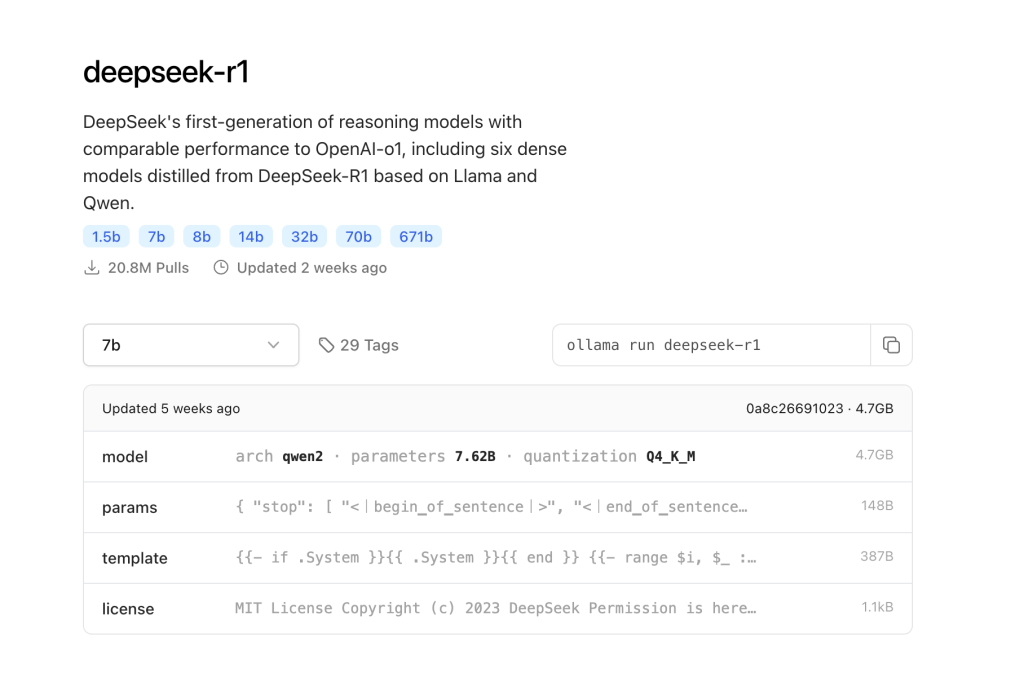
Lista modeli
Lista modeli nieustannie się zmienia i na niej wiele modeli jest aktualizowanych.
Dostępna jest pod tym adresem a znaleźć tam można bardzo szczegółowe opisy oraz instrukcje.
Interfejs graficzny
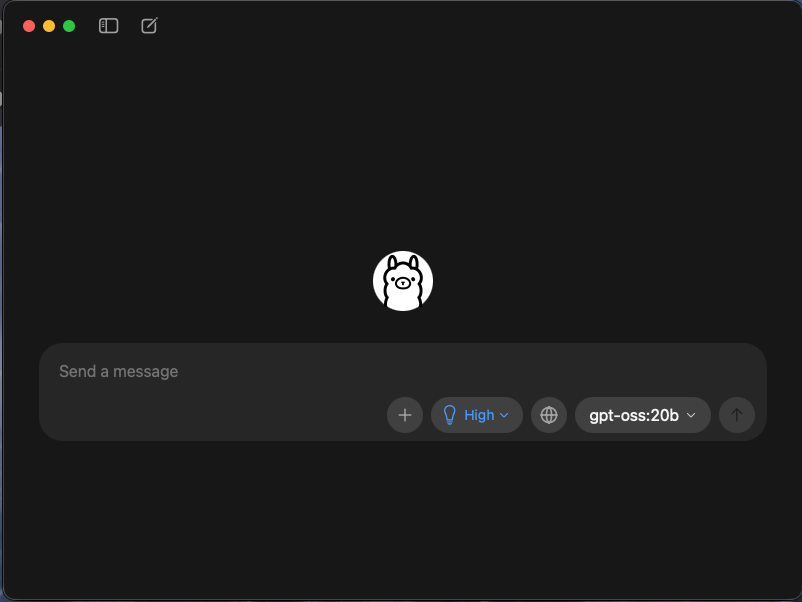
W dniu 30 lipca 2025 został wprowadzony interfejs graficzny który ułatwia zarządzanie jak i też komunikacje z modelami i ich testowanie. Interfejs jest prosty, lewym górnym rogu mamy przyciski do listy konwersacji i rozpoczęcia rozmów a przy rozmowie jest opcja jak mocno model ma “myśleć” przy konwersacji jak i też ma dostęp do wyszukiwania informacji.
W przypadku korzystania z wyszukiwania to wymagane jest konto ollamy które jest darmowe.

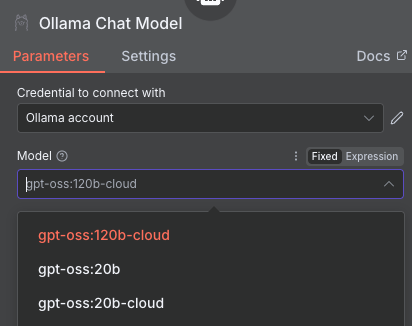
Gdy chcemy użyć modeli w chmurze np. w n8n to ważne jest by najpierw z nim porozmawiać z interfejsu graficznego by pojawił się na liście wyboru lub za pomocą polecenia ollama run gpt-oss:20b-cloud.
Tekst został zaktualizowany 5.11.2025.



