




Spis treści
HunyuanCustom – multimodalny system generowania spersonalizowanych materiałów wideo
8 maja 2025 roku firma Tencent udostępniła kody źródłowe oraz wagi modelu HunyuanCustom – zaawansowanego systemu do generowania spersonalizowanych materiałów wideo. Model został zaprojektowany z myślą o zachowaniu spójności postaci przy jednoczesnym oferowaniu wszechstronnych możliwości sterowania generowaną treścią za pomocą różnych modalności wejściowych.
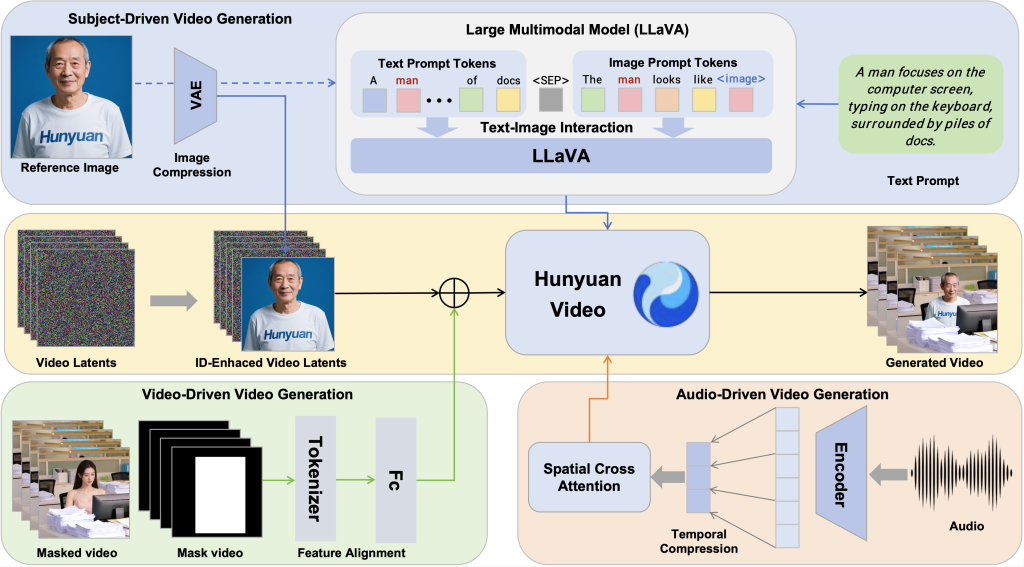
Architektura i kluczowe funkcje
HunyuanCustom opiera się na frameworku HunyuanVideo i wprowadza szereg innowacyjnych rozwiązań technologicznych. Model wykorzystuje moduł fuzji tekstu i obrazu bazujący na architekturze LLaVA, co zapewnia lepsze zrozumienie multimodalne. Dodatkowo zastosowano moduł wzmocnienia ID obrazu, który wykorzystuje konkatenację czasową do zachowania spójności cech tożsamości postaci w kolejnych klatkach wideo.
System obsługuje cztery typy danych wejściowych:
- Tekst – określający scenariusz i kontekst sceny
- Obraz – definiujący wygląd postaci lub obiektów
- Dźwięk – umożliwiający generowanie wideo z odpowiednio zsynchronizowaną mową
- Wideo – pozwalające na podmianę obiektów w istniejącym materiale
Do obsługi dźwięku HunyuanCustom wykorzystuje moduł AudioNet realizujący hierarchiczne wyrównanie poprzez przestrzenną cross-attention, natomiast dla wideo zastosowano moduł wstrzykiwania wykorzystujący sieć wyrównywania cech typu patchify.
Wymagania sprzętowe
Do uruchomienia HunyuanCustom potrzebne są znaczące zasoby obliczeniowe. Minimalny wymóg to 24 GB pamięci GPU, ale dla optymalnej jakości zalecane jest 80 GB. Model został przetestowany na systemie Linux z 8 kartami graficznymi. Dla użytkowników dysponujących mniejszymi zasobami dostępne są wersje zoptymalizowane pod kątem wydajności.
Praktyczne zastosowania
HunyuanCustom otwiera nowe możliwości w szeregu zastosowań:
- Wirtualne reklamy z zachowaniem wierności postaci
- Interaktywne wirtualne przymierzalnie
- Tworzenie śpiewających awatarów sterowanych dźwiękiem
- Edycja materiałów wideo poprzez podmianę obiektów
- Spersonalizowane animacje z pojedynczego zdjęcia
OLMo 2 1B – mały model AI, który przewyższa konkurencję od gigantów technologicznych
Nonprofit AI research institute (Ai2) udostępniło nowy model sztucznej inteligencji OLMo 2 1B o wielkości zaledwie 1 miliarda parametrów. Co wyróżnia ten model, to fakt, że według twórców, przewyższa on podobnej wielkości modele od Google, Meta oraz Alibaba w kilku kluczowych testach wydajności. Model jest częścią rosnącego trendu tworzenia mniejszych, ale wydajnych modeli AI.

Kluczowe cechy techniczne
OLMo 2 1B został wytrenowany na imponującym zbiorze 4 bilionów tokenów pochodzących z danych publicznie dostępnych, wygenerowanych przez AI oraz ręcznie tworzonych źródeł. Dla porównania, milion tokenów to około 750 000 słów. Ta intensywna ekspozycja na dane przekłada się na wyjątkowe zdolności modelu pomimo jego relatywnie niewielkiego rozmiaru.
W testach benchmarkowych model uzyskał lepsze wyniki niż Google Gemma 3 1B, Meta Llama 3.2 1B oraz Alibaba Qwen 2.5 1.5B. Szczególnie dobrze wypadł w teście GSM8K mierzącym rozumowanie arytmetyczne oraz TruthfulQA oceniającym dokładność faktyczną. Model wykazał również wysoką skuteczność w teście DROP (rozumienie tekstu) oraz IFEval (wykonywanie instrukcji).
Co wyjątkowe, OLMo 2 1B jest w pełni otwartoźródłowy – Ai2 udostępniło nie tylko sam model, ale również cały kod oraz zestawy danych (Olmo-mix-1124 i Dolmino-mix-1124) używane do jego treningu. Model jest dostępny na licencji Apache 2.0 na platformie Hugging Face, co pozwala na pełną replikację modelu od podstaw.
Praktyczne zastosowania
Główną zaletą małych modeli językowych jest możliwość uruchamiania ich na przeciętnym sprzęcie konsumenckim. OLMo 2 1B może działać na nowoczesnym laptopie, a nawet urządzeniu mobilnym, co czyni go dostępnym dla szerokiego grona programistów i entuzjastów z ograniczonymi zasobami sprzętowymi.
Model można wykorzystać do podstawowej interakcji konwersacyjnej, pomocy z kodem czy prostszych zadań rozumowania, bez konieczności korzystania z drogich zasobów obliczeniowych. Do uruchomienia modelu wystarczy nowoczesny procesor z minimum 8 GB pamięci RAM, choć dla szybszej pracy zalecana jest karta graficzna z przynajmniej 8-12 GB pamięci VRAM.
Twórcy ostrzegają jednak, że jak wszystkie modele AI, OLMo 2 1B może generować problematyczne treści, w tym szkodliwe lub faktycznie niepoprawne informacje. Z tego powodu Ai2 nie zaleca wdrażania modelu w środowiskach komercyjnych bez odpowiednich zabezpieczeń.
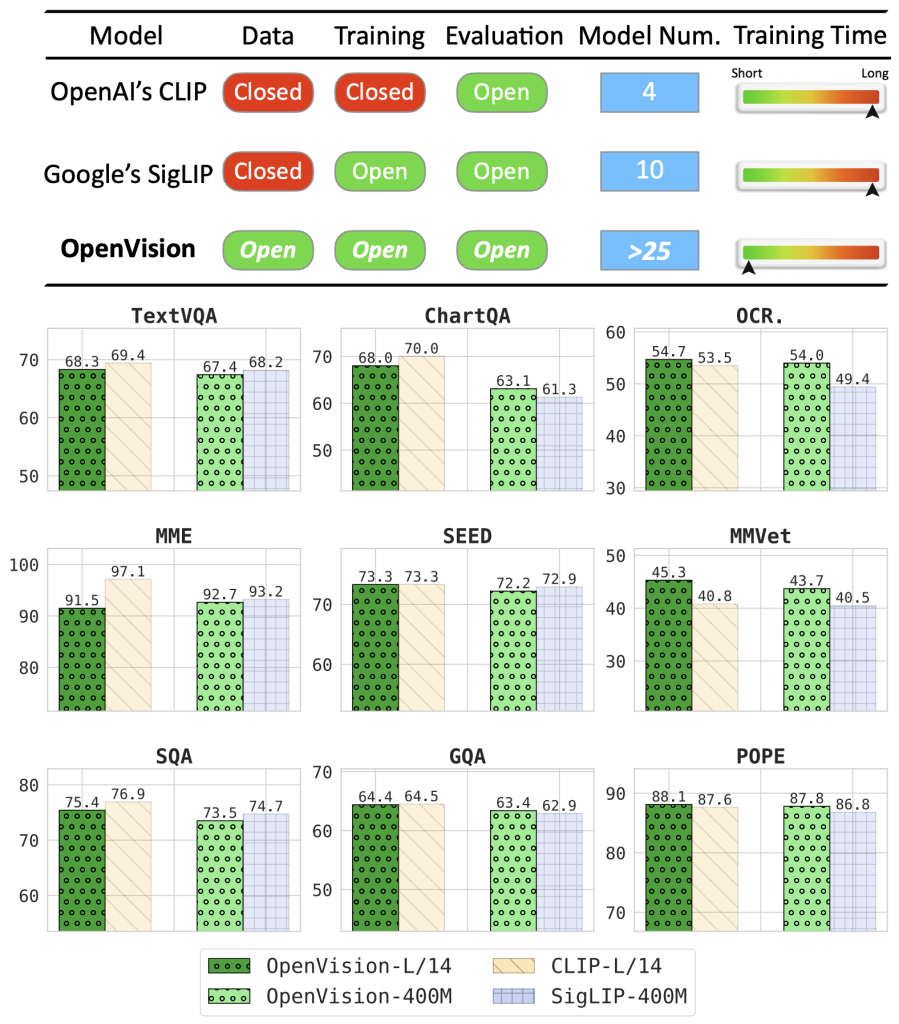
OpenVision – przełomowy otwartoźródłowy koder wizyjny jako alternatywa dla modeli OpenAI i Google
W świecie modeli sztucznej inteligencji przetwarzających dane wizualne pojawił się istotny nowy gracz. Uniwersytet Kalifornijski w Santa Cruz opublikował OpenVision – kolekcję koderów wizyjnych zaprojektowanych jako alternatywa dla istniejących rozwiązań, takich jak czteroletni CLIP od OpenAI czy ubiegłoroczny SigLIP od Google.
Czym są kodery wizyjne i dlaczego są istotne
Koder wizyjny to rodzaj modelu AI, który przekształca treści wizualne (zazwyczaj statyczne obrazy przesyłane przez użytkowników) w dane numeryczne, które mogą być interpretowane przez modele nieobrazowe, w tym duże modele językowe (LLM). Te kodery pełnią funkcję niezbędnego pomostu umożliwiającego wiodącym LLM przetwarzanie obrazów przesyłanych przez użytkowników, ułatwiając identyfikację różnych elementów, w tym tematów, kolorów i położenia obiektów w obrazie.
Kluczowe cechy techniczne OpenVision
OpenVision, udostępniony na licencji Apache 2.0 pozwalającej na użycie komercyjne, oferuje zróżnicowany zestaw 26 modeli o wielkości od 5,9 miliona do 632,1 miliona parametrów. Architektura systemu została zaprojektowana z myślą o różnorodnych scenariuszach wdrożeniowych – od większych modeli do zadań serwerowych wymagających wysokiej precyzji po mniejsze wersje zoptymalizowane pod kątem obliczeń brzegowych.
Szczególnie godna uwagi jest metoda treningu o progresywnej rozdzielczości, zaadaptowana z CLIPA. Podejście to polega na rozpoczęciu treningu z obrazami o niskiej rozdzielczości i stopniowym dostrajaniu modeli do wyższych rozdzielczości, co prowadzi do 2-3-krotnie szybszego procesu obliczeniowego w porównaniu do CLIP i SigLIP – bez uszczerbku dla wydajności.
Praktyczne zastosowania w środowisku biznesowym
Znaczenie OpenVision dla zespołów technicznych w przedsiębiorstwach jest znaczące. Dla inżynierów zarządzających wdrożeniami LLM, OpenVision stanowi gotowe rozwiązanie ułatwiające integrację wysokowydajnych możliwości wizualnych bez polegania na nieprzejrzystych API stron trzecich lub restrykcyjnych licencjach modelowych.
Zespoły zajmujące się orkiestracją AI zyskują dostęp do modeli o różnej wielkości – od bardzo małych koderów do zastosowań brzegowych po większe modele wysokiej rozdzielczości do aplikacji w chmurze. Inżynierowie danych mogą wykorzystać OpenVision do wzbogacenia potoku analitycznego opartego na obrazach, gdzie dane strukturalne są uzupełniane danymi wizualnymi (np. dokumentami czy zdjęciami produktów).
Co istotne, przejrzysta architektura i odtwarzalny potok OpenVision pozwalają zespołom bezpieczeństwa na ocenę i monitorowanie potencjalnych luk w modelu, co jest kluczowe w sektorach regulowanych przetwarzających wrażliwe dane wizualne.
Źródła
- New fully open source vision encoder OpenVision arrives to improve on OpenAI’s Clip, Google’s SigLIP
- Ai2’s new small AI model outperforms similarly-sized models from Google, Meta | TechCrunch
- allenai/OLMo-2-0425-1B – Hugging Face
- AI2’s OLMo 2 1B model rivals offerings from leading tech firms
- OpenVision: A Fully-Open, Cost-Effective Family of Advanced Vision Encoders for Multimodal Learning
- Hugging Face – tencent/HunyuanCustom
- arXiv:2505.04512 – HunyuanCustom: A Multimodal-Driven Architecture for Customized Video Generation
- GitHub – Tencent/HunyuanCustom



