




Transformacja danych stanowi serce każdego workflow’u automatyzacji w n8n. Bez względu na to, czy pobierasz informacje z API, przetwarzasz pliki CSV czy łączysz dane z różnych źródeł, odpowiednie narzędzia transformacji decydują o skuteczności całego procesu. W tym artykule omówimy wszystkie dostępne w n8n narzędzia do przetwarzania danych, które pozwolą Ci stworzyć zaawansowane przepływy pracy.
Podstawowe narzędzia transformacji – kategoria Popular
Code to najbardziej uniwersalne narzędzie w arsenale n8n. Umożliwia uruchamianie niestandardowego kodu JavaScript lub Python bezpośrednio w workflow. Jest to idealne rozwiązanie gdy standardowe nody nie oferują wymaganej funkcjonalności. Możesz wykorzystywać go do skomplikowanych obliczeń, parsowania nietypowych formatów danych czy implementacji złożonej logiki biznesowej. Code Node przyjmuje dane wejściowe jako tablicę obiektów JSON i zwraca wyniki w tym samym formacie, co zapewnia płynną integrację z resztą workflow’u.
Date & Time Node specjalizuje się w manipulacji wartościami czasu i dat. W erze globalizacji i automatyzacji zarządzanie strefami czasowymi, formatowaniem dat i obliczeniami temporalnymi jest kluczowe. Ten node pozwala na konwersję między formatami, dodawanie czy odejmowanie okresów czasowych, oraz dostosowywanie dat do lokalnych konwencji. Szczególnie przydatny przy integracjach z systemami CRM, kalendarzami czy narzędziami do planowania.
Edit Fields (Set) Node umożliwia precyzyjną kontrolę nad strukturą danych. Za jego pomocą możesz dodawać nowe pola, modyfikować istniejące czy usuwać niepotrzebne informacje. Node ten wspiera wyrażenia dynamiczne, co oznacza, że wartości pól mogą być obliczane na podstawie innych danych w workflow. To podstawowe narzędzie do dostosowywania struktury danych przed przekazaniem ich do kolejnych nodeów czy zewnętrznych systemów.
Zarządzanie ilością elementów – kategoria Add or remove items
Filter Node działa jak inteligentny sito dla Twoich danych. Pozwala na tworzenie warunków, które określają które elementy powinny zostać przekazane dalej w workflow. Możesz filtrować dane na podstawie wartości pól, typów danych czy złożonych wyrażeń logicznych. Jest niezbędny przy pracy z dużymi zbiorami danych, gdzie potrzebujesz wyodrębnić tylko określone rekordy spełniające konkretne kryteria.
Limit Node kontroluje przepływ danych poprzez ograniczanie liczby elementów przekazywanych do kolejnych kroków workflow. Szczególnie przydatny przy pracy z API, które mogą zwracać tysiące rekordów, gdy potrzebujesz tylko pierwszych kilku. Możesz określić maksymalną liczbę elementów lub implementować paginację dla lepszego zarządzania zasobami systemowymi.
Remove Duplicates Node automatycznie identyfikuje i usuwa zduplikowane rekordy z zestawu danych. Możesz skonfigurować go do porównywania wszystkich pól lub tylko wybranych kluczy identyfikacyjnych. To kluczowe narzędzie przy konsolidacji danych z różnych źródeł, gdzie duplikaty mogą naturalnie występować.
Split Out Node wykonuje operację odwrotną do agregacji – dzieli pojedynczy element zawierający listę na wiele oddzielnych elementów. Jest niezbędny gdy otrzymujesz dane w postaci zagnieżdżonych struktur, a potrzebujesz przetwarzać każdy element indywidualnie. Przykładowo, gdy API zwraca pojedynczy obiekt z tablicą produktów, Split Out pozwoli Ci przekształcić go w strumień pojedynczych produktów.
Łączenie i agregacja danych – kategoria Combine items
Aggregate Node łączy wiele elementów w pojedynczą strukturę danych. To potężne narzędzie pozwala na grupowanie rekordów według określonych kryteriów i wykonywanie operacji agregujących jak sumowanie, liczenie czy znajdowanie wartości ekstremalnych. Szczególnie przydatny przy generowaniu raportów czy podsumowań z dużych zbiorów danych.
Merge Node umożliwia łączenie danych pochodzących z różnych ścieżek workflow’u. Możesz konfigurować różne strategie łączenia – od prostego dołączania wszystkich danych po zaawansowane operacje podobne do JOIN w bazach danych. Jest niezbędny w scenariuszach gdzie musisz wzbogacić dane z jednego źródła informacjami z innego.
Summarize Node generuje statystyki i podsumowania z zestawów danych w sposób podobny do tabel przestawnych w Excel. Pozwala na grupowanie danych według wybranych wymiarów i obliczanie metryk agregowanych. Idealny do tworzenia dashboardów, raportów sprzedażowych czy analiz wydajności.
Konwersja formatów danych – kategoria Convert data
Compression Node obsługuje kompresję i dekompresję plików w różnych formatach. Przydatny przy pracy z dużymi plikami, gdzie oszczędność miejsca i szybkość transferu są kluczowe. Wspiera popularne formaty jak ZIP, GZIP czy inne algorytmy kompresji.
Convert to File Node przekształca dane JSON w format binarny, umożliwiając generowanie plików do pobrania lub przesłania. Szczególnie użyteczny przy eksportowaniu wyników przetwarzania do formatów jak CSV, PDF czy inne dokumenty.
Crypto Node zapewnia funkcjonalności kryptograficzne w workflow. Umożliwia hashowanie danych, generowanie podpisów cyfrowych, szyfrowanie i deszyfrowanie informacji. Kluczowy element przy budowaniu bezpiecznych integracji i ochronie wrażliwych danych.
Edit Image Node pozwala na podstawowe operacje edycji obrazów bezpośrednio w workflow. Możesz zmieniać rozmiary, dodawać ramki, nakładać tekst czy wykonywać inne transformacje graficzne. Przydatny w procesach automatyzacji marketingowej czy generowania materiałów wizualnych.
Extract from File Node wykonuje operację odwrotną do Convert to File – przekształca dane binarne z powrotem do formatu JSON. Umożliwia odczytywanie i parsowanie różnych typów plików w ramach workflow.
HTML Node specjalizuje się w przetwarzaniu dokumentów HTML. Pozwala na ekstrakcję określonych elementów za pomocą selektorów CSS, konwersję HTML na tekst czy inne operacje związane z przetwarzaniem stron internetowych. Niezbędny przy web scrapingu i automatyzacji procesów związanych z treściami internetowymi.
Narzędzia pomocnicze – kategoria Other
Rename Keys Node umożliwia zmianę nazw pól w obiektach danych. Jest szczególnie przydatny przy integracjach między systemami używającymi różnych konwencji nazewniczych. Pozwala na mapowanie pól bez konieczności pisania niestandardowego kodu.
Sort Node organizuje dane według określonych kryteriów sortowania. Możesz sortować po pojedynczych polach lub złożonych kluczach, w kolejności rosnącej lub malejącej. Dodatkowo oferuje opcję losowego tasowania elementów, co może być przydatne w niektórych scenariuszach biznesowych.
Przykłady użycia
Utwórzmy automatyzacje z następującymi blokami by przećwiczyć.
Wybierz node code i wprowadź poniższy kod.
return [
{
json: {
liczby: "1;2;3;4;5;6;7;8"
}
}
];Następnie wybierz następujące node’y:
- Edit fields
- Split out
- Limit
- FIlter
- Merge
Ułóż je dokładnie w takiej kolejności i dodatkowo skopiuj blok wraz z zawartością Code.
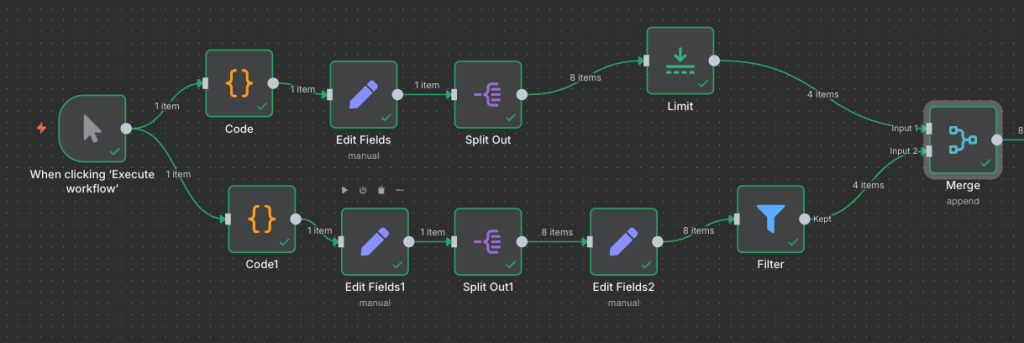
Teraz przechodzimy w ustawienia górnych node’ów, po wykonaniu pierwszego Code.
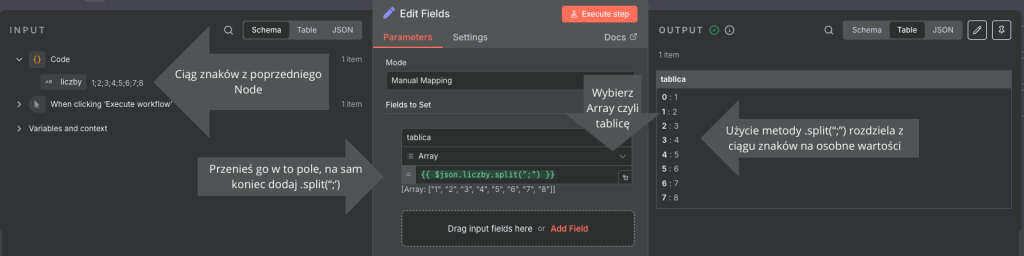
Użycie metody .split(";")pozwala rozdzielić ciąg znaków na osobne elementy, w zależności jakie mamy dane, jeżeli mamy inny znak należy użyć tego znaku pomiędzy cudzysłowami np. .split("-") dla znaku minus.
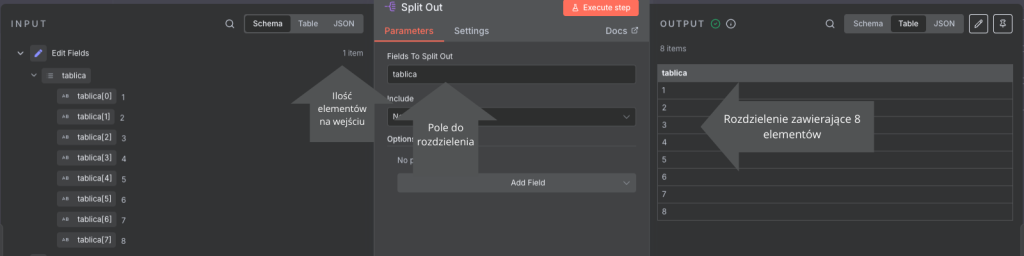
Dla następnego bloku Split Out przenosimy który element chcemy rozdzielać do pola Fields To Split Out.
I co istotne, dlaczego się wykonuje tą operacje, przed wykonaniem tego bloku mamy jeden element mający osiem wartości a po tej zmianie mamy osiem elementów mających po jednej wartości. Użycie tego bloku i takiej manipulacji danymi zawsze zależy od indywidualnych potrzeb.
Następnym polem jest limit i jest dość prosty bo ogranicza nam ilość przechodzących elementów (co potrafi być przydatne jak testujemy workflow i chcemy przetestować działanie na paru elementach a nie wczytywać całą bazę danych od razu).
By dodać limit wprowadź liczbę w pole Max Items, w obecnym przypadku będzie to 4.
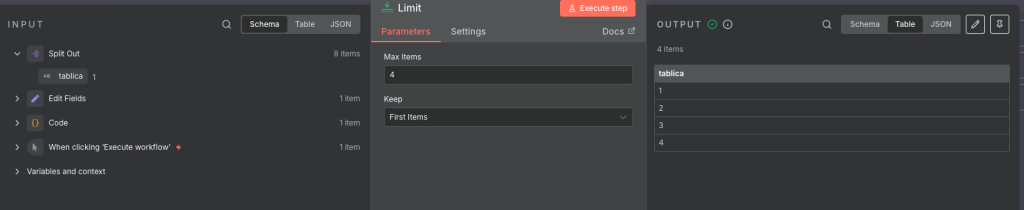
Następnym blokiem jest Merge i zostawiamy go na domyślnych ustawieniach, ten blok służy łączeniu danych z różnych źródeł więc na tym przykłądzie wrócimy do niego później, teraz przejdziemy do drugiego poziomu przykładu automatyzacji.
W podanym przykładzie pokażę jedynie różnice w polach.
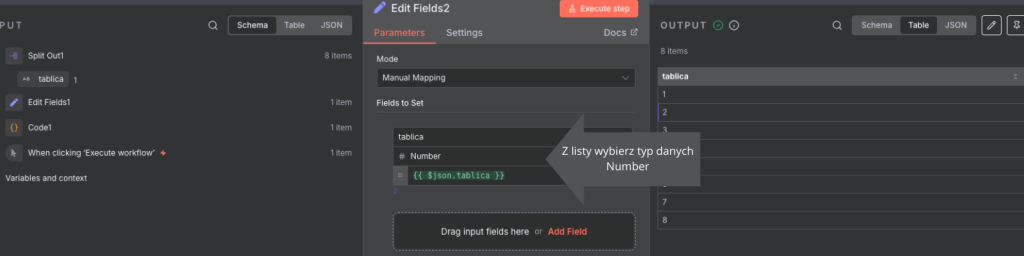
Używając nazw z obrazu przedstawiający przykład Edit Fields1 oraz Split Out1 nie mają żadnych różnic, te zaczynają się w Edit Fields2, przenosząc pole do ustawienia zmieniamy typ danych, tym razem wybieramy Number, od teraz te dane są traktowane jako dane liczbowe na których można przeprowadzać działania arytmetyczne, gdzie na łańcuchach znaków nie ma takiej możliwości.
Następnym node’m jest Filter który sprawdza wartości na podanym polu, w tym przypadku ustawiamy jak poprzednio pole do sprawdzenia i wybieramy opcje w Number -> is greater than z ustawieniem na 4.
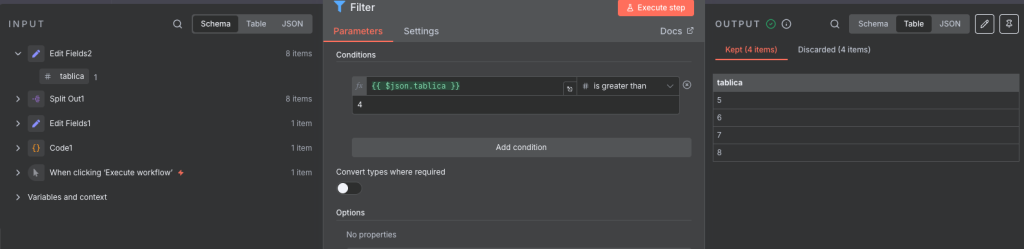
Jak można zauważyć zwróciło 4 rekordy czyli liczby 5,6,7,8.
Teraz można wykonać całe workflow i w Merge ukaże się lista 8 elementów.
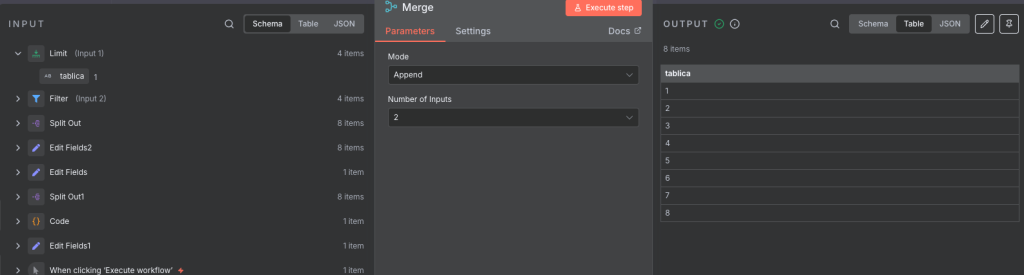
W parametrze Number of inputs można zmieniać ile może przyjmować node źródeł do połączenia.
Ten krótki przykład możesz zaimportować do swojej instancji, wystarczy wejść na repozytorium pod adresem i wybrać plik automatyzacji JSON klikając download raw file i w n8n tworząc nowe worklfow wybierając opcje import from file.
Podsumowanie
Skuteczne wykorzystanie narzędzi transformacji wymaga zrozumienia przepływu danych w n8n. Każdy node przetwarza dane jako tablicę obiektów JSON, gdzie każdy element reprezentuje jeden rekord do przetworzenia. Ta struktura zapewnia spójność i przewidywalność w całym workflow.
Przy budowaniu złożonych przepływów danych warto stosować podejście stopniowe. Zacznij od prostych transformacji jak filtrowanie czy sortowanie, następnie przechodź do bardziej zaawansowanych operacji jak agregacja czy łączenie danych. Każdy krok powinien być testowany indywidualnie przed integracją z resztą workflow’u.
Kombinowanie różnych node’ów transformacji pozwala na tworzenie potężnych pipeline’ów przetwarzania danych. Przykładowo, możesz użyć Filter Node do wybrania odpowiednich rekordów, następnie Aggregate Node do grupowania wyników, a na końcu Convert to File Node do eksportowania raportu w formacie CSV.
Pamiętaj o wydajności przy pracy z dużymi zbiorami danych. Narzędzia jak Limit Node mogą znacząco wpłynąć na czas wykonania workflow’u, szczególnie przy integracjach z zewnętrznymi API. Rozważ implementację paginacji i przetwarzania wsadowego dla optymalnej wydajności.
Transformacja danych w n8n to sztuka łączenia odpowiednich narzędzi w logiczną sekwencję operacji. Dzięki bogatemu zestawowi nodeów możesz zautomatyzować nawet najbardziej złożone procesy przetwarzania danych, oszczędzając czas i minimalizując ryzyko błędów ludzkich.




