






Instytut Innowacji Technologicznych (TII) z Abu Dhabi opublikował 31 marca 2026 roku model Falcon Perception – wczesno-fuzyjny Transformer o 600 milionach parametrów przeznaczony do gruntowania w otwartym słowniku oraz segmentacji instancji sterowanej językiem naturalnym. Model jest dostępny na platformie Hugging Face jako projekt open source i stanowi część rodziny modeli Falcon, rozwijanych od kilku lat przez TII w ramach emirackiej strategii suwerenności technologicznej.
Problem, który rozwiązuje Falcon Perception
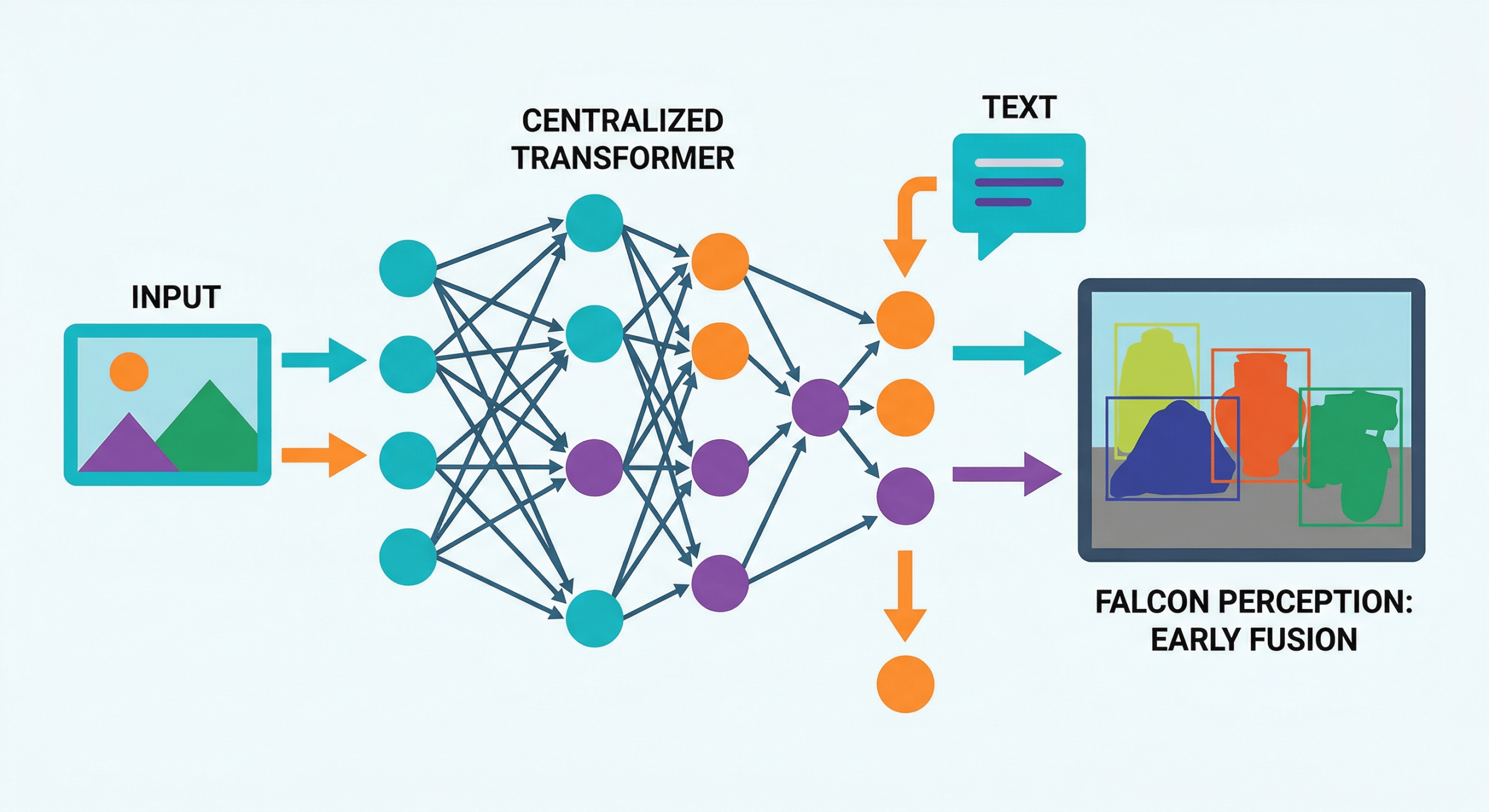
Większość dotychczasowych systemów wizyjno-językowych opiera się na architekturze dwuetapowej: oddzielny koder obrazu przetwarza piksele, a następnie oddzielny moduł językowy interpretuje uzyskane reprezentacje. Takie podejście zwiększa złożoność wdrożenia, opóźnienie inferencji oraz zużycie zasobów obliczeniowych. Falcon Perception proponuje inne podejście: jeden stos Transformera przetwarza łącznie patche obrazu i tokeny tekstu już od pierwszej warstwy, co eliminuje potrzebę późnej fuzji i oddzielnych głowic enkodujących.
Architektura: jedna sieć, dwa zachowania
Kluczowym elementem architektury jest hybrydowa maska uwagi, która pozwala temu samemu modelowi zachowywać się jednocześnie jak enkoder wizyjny i autoregresjny dekoder tekstowy.
- Tokeny obrazu uczestniczą w uwadze dwukierunkowej – widzą wszystkie inne patche wizyjne, co pozwala budować globalny kontekst sceny, analogicznie do klasycznych enkoderów ViT.
- Tokeny tekstu i tokeny zadań uczestniczą w uwadze przyczynowej (kauzalnej) – widzą cały prefiks wizyjny oraz wcześniejsze tokeny tekstowe, co umożliwia sekwencyjne dekodowanie wyników.
Dzięki tej maskowaniu jeden backbone obsługuje oba tryby bez duplikowania wag czy stosowania zewnętrznych modułów fuzji. Model nie wymaga mechanizmu dopasowania węgierskiego (Hungarian matching) typowego dla architektur DETR, ponieważ segmentacja następuje przez iloczyn skalarny ukrytego stanu tokenu <seg> z nadpróbkowanymi cechami obrazu.
Chain-of-Perception: ustrukturyzowane dekodowanie instancji
Dla każdej wykrytej instancji model generuje krótką, ustrukturyzowaną sekwencję tokenów zadań w stałej kolejności:
<coord>– środek bounding boxa, dekodowany przez wyspecjalizowaną głowicę regresji<size>– wymiary bounding boxa; geometria jest re-injektowana jako cechy Fouriera, kondycjonując kolejne kroki<seg>– token maski, którego ukryty stan stanowi zapytanie do upsamplowanych cech obrazu, generując binarną maskę o pełnej rozdzielczości
Takie podejście, nazwane przez autorów Chain-of-Perception, analogiczne jest do koncepcji łańcucha myślenia (chain-of-thought) w modelach językowych – model buduje odpowiedź stopniowo, warunkując każdy krok wynikiem poprzedniego. Liczba generowanych instancji jest zmienna i nie wymaga z góry zdefiniowania maksymalnej wartości.
Wyniki i nowy benchmark PBench
TII przetestowało model na benchmarku SA-Co (Segment Anything Captioned), gdzie Falcon Perception osiągnął wynik 68,0 Macro-F1 wobec 62,3 uzyskanego przez SAM 3 firmy Meta. Największe zyski widoczne są w semantycznie trudnych kategoriach.
| Model | Parametry | SA-Co Macro-F1 | MCC (kalibracja obecności) |
|---|---|---|---|
| Falcon Perception | ~600M | 68,0 | 0,64 |
| SAM 3 (Meta) | znacznie większy | 62,3 | 0,82 |
Jedynym obszarem, gdzie SAM 3 zachowuje przewagę, jest kalibracja obecności (MCC 0,82 vs. 0,64) – Falcon ma tendencję do generowania nadmiarowych masek nawet wtedy, gdy obiekt nie jest obecny na obrazie. Autorzy wskazują to jako główny kierunek dalszych prac.
Równolegle TII wprowadził PBench – własny benchmark diagnostyczny, który segmentuje wyniki według konkretnych możliwości modelu:
- Rozumienie atrybutów obiektów (kolor, materiał, stan)
- Dezambiguacja wspomagana OCR (odróżnianie obiektów przez tekst na nich widoczny)
- Ograniczenia przestrzenne (lewa/prawa strona, nad/pod)
- Relacje między obiektami
- Gęste sceny długokontekstowe z dużą liczbą instancji
Falcon OCR – siostrzany model dokumentowy
Razem z Falcon Perception TII opublikowało model Falcon OCR (300M parametrów), który stosuje tę samą architekturę wczesnej fuzji do ekstrakcji tekstu z dokumentów. Model zwraca zarówno zwykły tekst, jak i transkrypcję w formacie LaTeX dla równań matematycznych i układów tabelarycznych. Oba modele są dostępne w kolekcji tiiuae/falcon-perception na Hugging Face i mogą być uruchamiane lokalnie na sprzęcie klasy konsumenckiej dzięki niewielkiemu rozmiarowi parametrów.
Praktyczne zastosowania
Kompaktowa architektura i zunifikowana obsługa modality otwierają konkretne ścieżki wdrożeń:
- Robotyka i automatyzacja przemysłowa – szybka segmentacja obiektów na podstawie poleceń tekstowych bez konieczności trenowania dedykowanych klas
- Systemy wizyjne w pojazdach autonomicznych – identyfikacja i lokalizacja obiektów opisanych językiem naturalnym w czasie rzeczywistym
- Inteligentne przetwarzanie dokumentów – połączenie segmentacji layoutu z ekstrakcją tekstu w jednym przejściu przez sieć (Falcon OCR)
- Systemy edge AI – model o 600M parametrów może działać na urządzeniach brzegowych, serwerach bez GPU klasy datacenter lub w środowiskach z ograniczonym budżetem obliczeniowym
- Interaktywne wyszukiwanie wizualne – zapytania w stylu „znajdź wszystkie czerwone kubki na blacie” zwracają piksele, nie tylko etykiety klas
Model jest dostępny na licencji open source, co pozwala na fine-tuning na danych domenowych – szczególnie istotne dla zastosowań wymagających prywatności danych lub specyficznego słownictwa wizualnego, jak np. inspekcja jakości w produkcji czy analiza obrazowania medycznego.
Źródła
- Falcon Perception – Blog Hugging Face (TII)
- Karta modelu tiiuae/Falcon-Perception – Hugging Face
- Oficjalny komunikat prasowy TII – tii.ae
- Repozytorium kodu Falcon Perception – GitHub
- Karta modelu tiiuae/Falcon-OCR – Hugging Face
- UAE advances sovereign AI ambitions – Computer Weekly



