





Czym jest DeepSearcher?
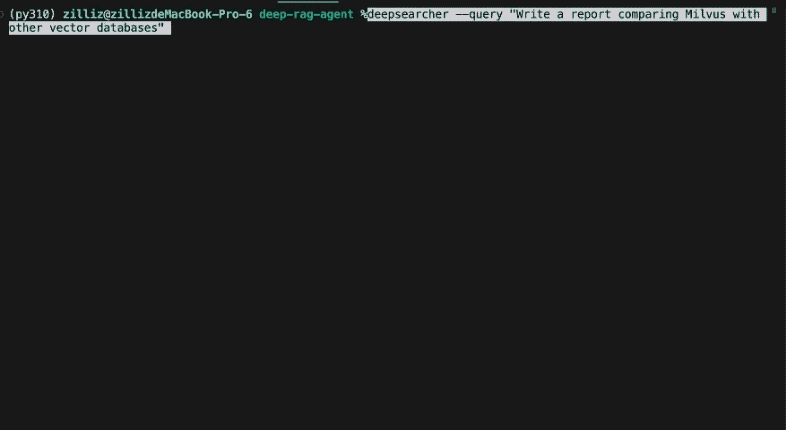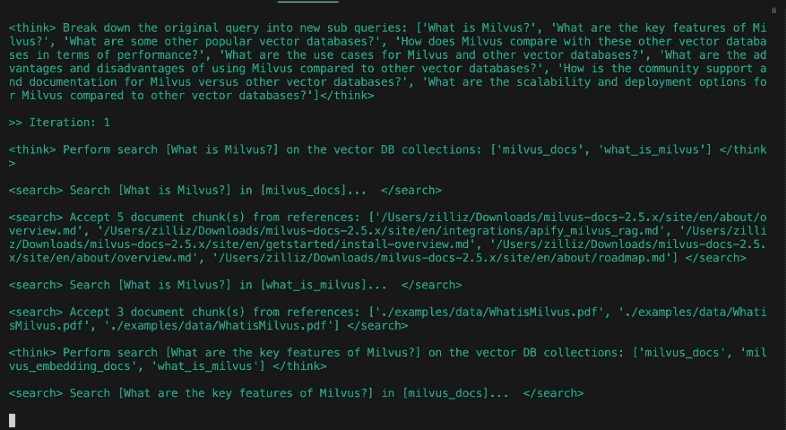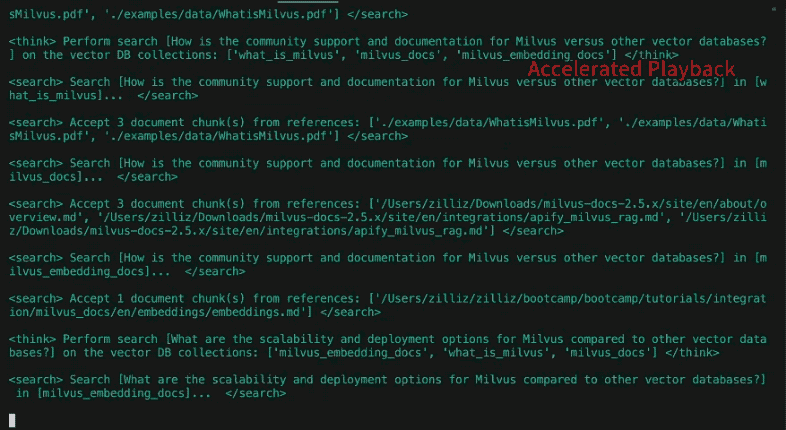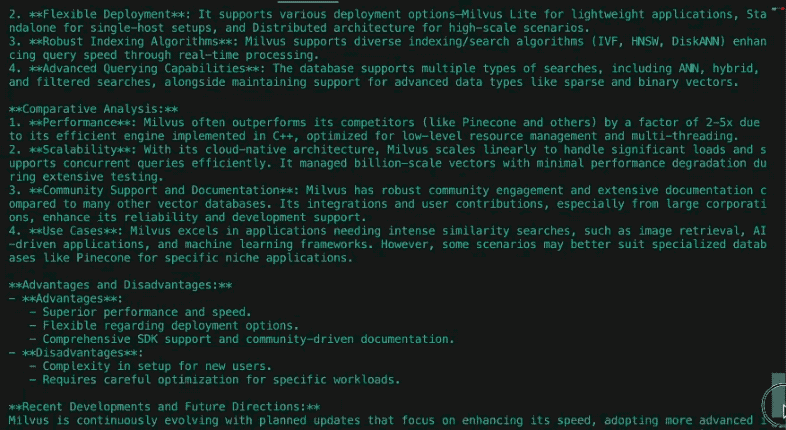
DeepSearcher to projekt open source opracowany przez Zilliz, który łączy zaawansowane modele językowe (LLM) z bazami danych wektorowymi w celu przeprowadzania analiz, wyszukiwania i generowania wniosków na podstawie danych prywatnych przedsiębiorstwa. Napisana w Pythonie aplikacja stanowi alternatywę dla komercyjnych rozwiązań typu deep research, umożliwiając organizacjom pełną kontrolę nad całym procesem oraz zachowanie poufności informacji.
Projekt łączy potencjał modeli takich jak DeepSeek R1, OpenAI o-series, Claude Sonnet czy Qwen3 z możliwościami baz wektorowych. Dzięki temu narzędziem mogą posługiwać się zarówno zespoły badawcze, jak i systemy zarządzania wiedzą korporacyjną czy inteligentne platformy Q&A.
Kluczowe funkcjonalności
DeepSearcher wyróżnia się kilkoma istotnymi cechami, które czyni go praktycznym rozwiązaniem dla przedsiębiorstw:
- Wyszukiwanie na danych prywatnych – system maksymalizuje wykorzystanie wewnętrznych zasobów informacyjnych firmy, zapewniając bezpieczeństwo danych. W razie potrzeby może uzupełniać wyniki zawartością z internetu.
- Zarządzanie bazami wektorowymi – wspiera Milvus i Zilliz Cloud, umożliwiając podział danych na partycje dla wydajnego wyszukiwania.
- Elastyczne modele embeddingów – obsługuje wiele modelów do reprezentacji wektorowej, pozwalając wybrać najlepszą opcję dla konkretnego przypadku użycia.
- Wsparcie wielu LLM – integracja z DeepSeek, OpenAI, Claude, Gemini i wieloma innymi modelami.
- Ładowanie dokumentów – obsługuje pliki lokalne (PDF, tekstowe), z opcją crawlingu stron internetowych (w rozwoju).
Architektura i konfiguracja
Instalacja DeepSearcher jest prosta – wystarczy wirtualne środowisko Pythona (rekomendowana wersja 3.10) i polecenie pip install deepsearcher. Projekt umożliwia wybór komponentów zgodnie z potrzebami organizacji.
Konfiguracja odbywa się poprzez obiekt Configuration, który definiuje:
- Model LLM – wybór dostawcy i konkretnego modelu (np. „o1-mini” od OpenAI lub „deepseek-reasoner” od DeepSeek).
- Model embeddingów – reprezentacja wektorowa tekstu (np. „text-embedding-ada-002” lub modele open-source).
- Bazę wektorową – Milvus z możliwością lokalnego przechowywania w pliku lub zdepliniowanego serwera.
- Loader plików – narzędziem do przetwarzania dokumentów (PDF, teksty).
- Web crawler – FireCrawl, Crawl4AI lub Jina Reader do pobierania zawartości z internetu.
Deweloperzy mogą również uruchomić DeepSearcher w trybie usługi FastAPI, dostępnej poprzez interfejs webowy pod adresem http://localhost:8000/docs.
Praktyczne zastosowania
DeepSearcher znajduje zastosowanie w scenariuszach wymagających głębokich analiz i generowania raportów:
- Systemy zarządzania wiedzą – organizowanie i przeszukiwanie wewnętrznych repozytoriów dokumentów.
- Inteligentne Q&A – automatyczne odpowiadanie na pytania pracowników na podstawie bazy dokumentów.
- Retrieval-Augmented Generation (RAG) – generowanie wniosków i raportów na podstawie konkretnych danych.
- Analiza konkurencyjna – zbieranie i syntezowanie informacji z publicznych źródeł.
- Badania rynkowe – automatyczne generowanie raportów na podstawie zaindeksowanych artykułów i danych.
Obecność wielu modeli LLM umożliwia eksperymenty – małe modele są szybsze, ale duże modele reasoning (takie jak DeepSeek R1 czy OpenAI o3) oferują głębszą analizę. Projekt rekomenduje do poważnych zastosowań wykorzystywanie dużych modeli reasoning, ponieważ mniejsze modele mogą mieć problemy z przestrzeganiem formatu wyjścia.
Integracja z ekosystemem open source
DeepSearcher integruje się z popularnym ekosystemem narzędzi:
- Milvus – otwarta baza wektorowa, idealna dla małych i dużych wdrożeń.
- Ollama – lokalne uruchomienie modeli open-source bez konieczności subskrypcji.
- Docling – zaawansowane przetwarzanie PDF i dokumentów.
- Crawl4AI – automatyczne pobieranie zawartości stron.
Ta modułowość czyni DeepSearcher elastycznym – firmy mogą budować rozwiązania dostosowane do swoich wymagań technicznych i budżetowych.
Ograniczenia i przyszłe plany
Projekt jest w fazie aktywnego rozwoju. Obecnie web crawling jest w wersji rozwojowej, a równocześnie zespół pracuje nad wsparciem dla dodatkowych baz wektorowych (FAISS, Qdrant) i modeli LLM. Projekt oferuje RESTful API oraz wsparcie dla różnych wdrożeń — od lokalnych instancji Milvus po usługę zarządzaną Zilliz Cloud.
DeepSearcher wykazuje aktywne zaangażowanie społeczności – projekt na GitHub’ie ma ponad 7 tys. gwiazdek i 683 forki, co wskazuje na rosnące zainteresowanie rozwiązaniami RAG i agentic reasoning w środowisku open source.



