





Streszczenie AI
Ollama ewoluuje z lokalnego narzędzia do uruchamiania modeli AI w chmurze, oferując oficjalne cloudowe API i kompatybilność z OpenAI/Anthropic, co umożliwia korzystanie z otwartych modeli bez lokalnej infrastruktury i praktycznie bezpłatnie. Użytkownicy mogą teraz łatwo przełączać się między lokalnymi a chmurowymi modelami (oznaczonymi %%WPOSCODEINLINE_0%%), korzystając z tego samego interfejsu API, co znacznie ułatwia prototypowanie, automatyzacje czy przetwarzanie danych wrażliwych.
Darmowe limity API są bardzo genericzne (np. przetwarzanie ~180 tys. słów w 10% sesyjnego limitu), a kompatybilność z popularnymi SDK-ami (np. OpenAI) sprawia, że Ollama staje się wszechstronną alternatywą dla komercyjnych rozwiązań, zarówno w edukacji, jak i biznesie.
Ollama od początku było narzędziem do uruchamiania modeli językowych lokalnie, na własnym sprzęcie. Przez długi czas była to jego jedyna rola. W 2025 roku projekt zaczął ewoluować w stronę chmury, oferując oficjalne API cloudowe oraz kompatybilność z popularnymi interfejsami, takimi jak OpenAI API i Anthropic Messages API. Dla programistów oznacza to jedno: możliwość korzystania z otwartych modeli AI bez potrzeby stawiania lokalnej infrastruktury i przynajmniej w pewnym zakresie bez opłat.
Czym jest Ollama Cloud i jak działa?
Ollama uruchomiła funkcję Cloud Models w trybie preview, która pozwala wysyłać zapytania do większych modeli uruchamianych na sprzęcie klasy datacenter, zamiast na lokalnym komputerze. Użytkownik korzysta z dokładnie tego samego interfejsu API co przy lokalnej instancji Ollamy, zmienia się tylko punkt końcowy (endpoint). Nie trzeba modyfikować kodu aplikacji ani narzędzi, które już działają z lokalną Ollamą.
Oficjalna strona podglądu chmury dostępna jest pod adresem ollama.com.
Jak szukać modeli Cloud?
Strona Ollamy umożliwia łatwe przeszukanie modeli które posiadają wariant w chmurze. Przy liście modeli wystarczy kliknąć Cloud (alternatywnie możesz kliknąć tutaj).

Modele z wariantem chmurowym nie mają podanego rozmiaru a zużycie ani i mają w nazwie :cloud, inicjujemy je tak jak inne modele z komendą np. ollama run qwen3-coder-next:cloud i w interfejsie Ollamy pojawia się w liście do wyboru.
Jak uzyskać klucz api?
Zainicjowanie modelu to nie wszystko, w sytuacji gdybyśmy chcieli użyć dowolnego modelu od lokalnego po ten w chmurze to z poziomu kodu(np. skryptu napisanego w Pythonie) nie mamy możliwości skorzystania z wyszukiwania które jest dostępne w kliencie Ollamy i do tej czynności też potrzebny jest klucz api.
By go uzyskać należy utworzyć konto na Ollama.com i po utworzeniu konta przejść do ustawień (settings) i Keys.
W tym miejscu należy skorzystać z Add API Key i skopiować klucz.
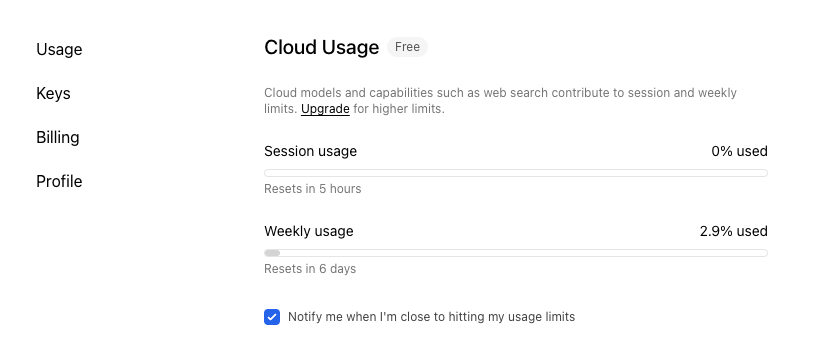
Limity użycia można śledzić w ustawieniach. Podział jest liczony na sesje 5h oraz tygodniowe.
Choć Ollama nie podaje oficjalnych liczb (np. konkretnej liczby tokenów), moje testy pokazują, że darmowe API jest zaskakująco hojne. Przetworzenie blisko 150 obszernych artykułów (ok. 180 000 słów) za pomocą modeli Cloud zużyło mniej niż 10% limitu sesji.
Oznacza to, że dla standardowych zastosowań – takich jak analiza dokumentów, pomoc w programowaniu czy obsługa prostego agenta AI – darmowe limity są niemal nieodczuwalne. Wyraźnie widać, że podział na sesje (resetowane co 5 godzin) ma na celu ukrócenie masowego „scrapowania” lub bardzo ciężkich procesów batchowych, a nie ograniczanie zwykłej pracy deweloperskiej.
Kompatybilność z OpenAI i Anthropic API
Jedną z kluczowych cech lokalnego serwera Ollamy jest jego kompatybilność z OpenAI API. Oznacza to, że każda aplikacja napisana pod OpenAI SDK może bez modyfikacji działać z Ollamą – wystarczy zmienić base URL na http://localhost:11434. To ogromna zaleta przy migracji istniejących projektów lub przy testowaniu otwartych modeli jako zamienników dla GPT.
Od wersji 0.14.0 Ollama obsługuje również Anthropic Messages API Compatibility. Praktyczne znaczenie tego kroku jest duże: narzędzia takie jak Claude Code mogą pracować z lokalnym lub cloudowym modelem Ollamy, podczas gdy aplikacja myśli, że komunikuje się z serwerami Anthropic. Konfiguracja sprowadza się do ustawienia zmiennych środowiskowych:
export ANTHROPIC_AUTH_TOKEN=ollama
export ANTHROPIC_BASE_URL=http://localhost:11434
Jeśli Ollama działa na zdalnej maszynie z mocniejszym GPU, wystarczy zamienić localhost na adres IP tego serwera. Dane nie opuszczają własnej infrastruktury, co ma znaczenie wszędzie tam, gdzie prywatność danych jest wymaganiem, a nie preferencją.
Przykład w kodzie:
import os
from ollama import Client
client = Client(
host='https://ollama.com/v1/chat/completions',
headers={'Authorization': 'Bearer ' + os.environ.get('OLLAMA_API_KEY')}
)
messages = [
{
'role': 'user',
'content': 'Why is the sky blue?',
},
]
for part in client.chat('gpt-oss:120b', messages=messages, stream=True):
print(part.message.content, end='', flush=True)W przypadku innych języków i implementacji należy użyć ich end pointa : https://ollama.com/v1/chat/completions
Praktyczne zastosowania cloudowego API Ollamy
Poniżej kilka scenariuszy, w których takie API ma realną wartość:
- Prototypowanie agentów AI – szybkie testy logiki agenta bez konieczności płacenia za każde wywołanie API podczas fazy developmentu
- Automatyzacje w n8n lub innych narzędziach no-code – integracja z workflowami opartymi na lokalnych lub cloudowych modelach Ollamy przez standardowy endpoint OpenAI-kompatybilny
- Analiza logów i incident response – lokalne lub cloudowe modele radzą sobie z analizą plików tekstowych i generowaniem skryptów bash, co sprawdza się przy pracy w terminalu
- Aplikacje wymagające prywatności danych – gdy dane nie mogą trafić do zewnętrznych usług, własna instancja Ollamy (lokalna lub na VPS) zapewnia pełną kontrolę
- Edukacja i nauka – bezpłatny dostęp do modeli 7B pozwala eksperymentować bez zakładania kont i kart kredytowych
Własny serwer Ollamy zamiast chmury – kiedy to ma sens?
Postawienie Ollamy na dedykowanym serwerze VPS z GPU jest alternatywą zarówno dla darmowego cloudowego API, jak i dla lokalnej instalacji na słabszym komputerze. Koszty hostingu z GPU są znacznie niższe niż subskrypcja API od OpenAI czy Anthropic przy intensywnym użytkowaniu, a przy tym zachowujesz pełną kontrolę nad modelami i danymi.
Serwer Ollamy wystawia REST API na porcie 11434 i obsługuje zapytania w formacie zgodnym z OpenAI. Można go zabezpieczyć przez reverse proxy (np. nginx z autoryzacją), a następnie udostępnić jako wewnętrzne API dla całego zespołu lub firmy. To szczególnie atrakcyjne w kontekście RODO i przetwarzania danych osobowych.
Modele dostępne przez Ollama API
Biblioteka modeli dostępnych przez Ollama obejmuje wszystkie główne rodziny open source:
- LLaMA 3 (Meta) – w wariantach 8B, 70B i 405B, jeden z najlepszych ogólnodostępnych modeli
- Mistral / Mixtral (Mistral AI) – modele MoE (Mixture of Experts) o wysokiej efektywności
- DeepSeek – mocny w zadaniach programistycznych i analitycznych
- Qwen (Alibaba) – modele wielojęzyczne z dobrymi wynikami na benchmarkach
- GPT-OSS (OpenAI) – open-weight modele od OpenAI na licencji Apache 2.0, dostępne lokalnie
Wybór modelu zależy od zadania. Przy kodowaniu i analizie technicznej większe modele (70B+) dają istotnie lepsze wyniki niż 7B, ale wymagają odpowiednio mocniejszego sprzętu lub płatnej warstwy cloudowej. Dla zadań tekstowych, streszczania i prostszych chatbotów modele 7B są w zupełności wystarczające.
Ollama zmienia się z narzędzia wyłącznie lokalnego w pełen stos do obsługi modeli open source – zarówno na własnym sprzęcie, jak i w infrastrukturze chmurowej, z jednolitym API dla obu scenariuszy.



