





Retrieval-Augmented Generation (RAG) to architektura, która rozwiązuje jeden z podstawowych problemów dużych modeli językowych: odpowiadanie wyłącznie na bazie własnej wiedzy treningowej, bez dostępu do konkretnych dokumentów użytkownika. Zamiast polegać na „pamięci” modelu, RAG w czasie każdego zapytania wyszukuje trafne fragmenty tekstu z zewnętrznej bazy wektorowej i dopiero te fragmenty przekazuje do modelu jako kontekst. Omawiana implementacja – złożona z dwóch plików: ingest.py i app.py – realizuje ten wzorzec w całości lokalnie, bez wysyłania danych do zewnętrznych API.
Architektura systemu
System składa się z dwóch niezależnych komponentów, które współdzielą jedną lokalną bazę wektorową:
- ingest.py – skrypt uruchamiany z linii poleceń; jego zadaniem jest jednorazowe (lub inkrementalne) przetworzenie plików PDF i zapisanie ich reprezentacji wektorowych do bazy Qdrant.
- app.py – interfejs webowy zbudowany w Streamlit; odpowiada za przyjmowanie pytań od użytkownika, wyszukiwanie odpowiednich fragmentów i generowanie odpowiedzi przez lokalny model językowy.
Oba skrypty korzystają z tego samego modelu embeddingowego, co jest warunkiem koniecznym poprawnego działania: wektory muszą żyć w tej samej przestrzeni, w której są potem wyszukiwane. Dane trafiają lokalnie na dysk (domyślna ścieżka: ./qdrant_db), a cały przepływ jest w pełni offline – jedynym wyjątkiem jest pierwsze pobranie modelu z Hugging Face.
Etap pierwszy: ingestowanie dokumentów (ingest.py)
Skrypt przyjmuje trzy argumenty: katalog z plikami PDF (--source), nazwę kolekcji (--collection) oraz opcjonalnie ścieżkę do bazy (--db_path). Architektura tego etapu obejmuje cztery sekwencyjne kroki:
- Ładowanie PDF: pliki są wczytywane przez
PyMuPDFLoader, który zachowuje metadane strony. Do każdego dokumentu dopisywana jest oryginalna ścieżka pliku jakosource_file– informacja ta jest później wyświetlana użytkownikowi jako źródło odpowiedzi. - Podział na chunki: tekst jest dzielony przez
RecursiveCharacterTextSplitterz rozmiarem okna 1000 znaków i nakładką 200 znaków. Nakładka gwarantuje, że zdania na granicy chunków nie tracą kontekstu. - Generowanie embeddingów: każdy chunk jest zamieniany na wektor 384-wymiarowy przez model
sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2. Model ten obsługuje ponad 50 języków, w tym polski, co czyni go adekwatnym wyborem dla wielojęzycznych zbiorów dokumentów. - Zapis do Qdrant: wektory są zapisywane do lokalnej instancji Qdrant z metryką kosinusową. Jeśli dana kolekcja jeszcze nie istnieje, zostaje automatycznie utworzona z właściwą konfiguracją (
size=384, distance=Distance.COSINE).
Ważna cecha implementacji: skrypt śledzi już przetworzone pliki w pliku stanu JSON ({collection}_state.json). Kolejne uruchomienie ingest.py na tym samym katalogu przetworzy wyłącznie nowe dokumenty, pomijając już zaindeksowane. Pozwala to na stopniowe rozbudowywanie bazy bez konieczności przetwarzania całego zbioru od nowa.
| Parametr | Wartość | Uzasadnienie |
|---|---|---|
| Model embeddingów | paraphrase-multilingual-MiniLM-L12-v2 | Wielojęzyczny, lekki (384 dim), dobra jakość na polskim tekście |
| Rozmiar chunka | 1000 znaków | Kompromis między granularnością a kontekstem |
| Nakładka (overlap) | 200 znaków | Zapobiega utracie sensu na granicy chunków |
| Metryka podobieństwa | Cosine | Standard dla modeli sentence-transformers |
| Baza wektorowa | Qdrant (lokalna) | Brak zależności od zewnętrznych serwerów |
Etap drugi: interfejs i generowanie odpowiedzi (app.py)
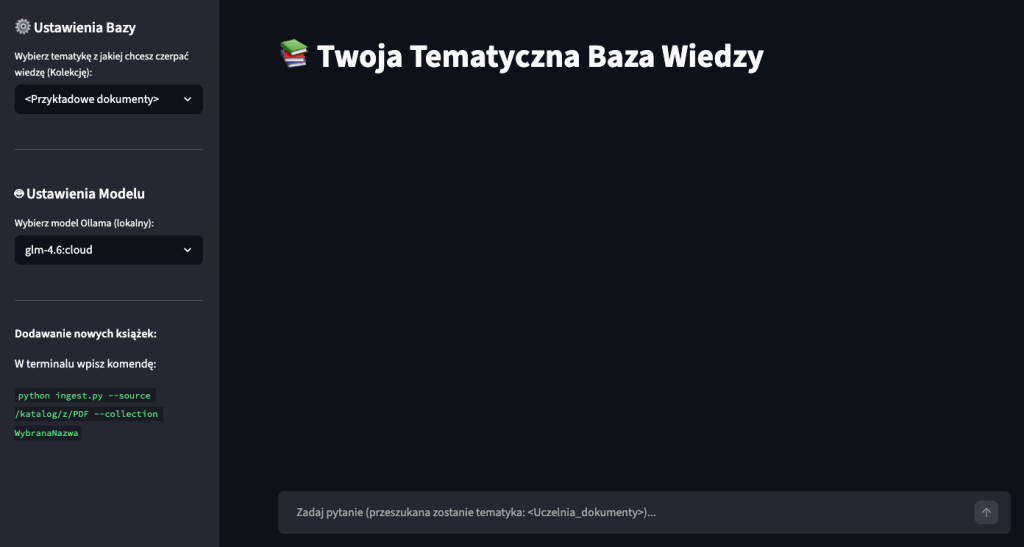
Plik app.py to aplikacja Streamlit realizująca drugą fazę RAG – retrieval i generation. Po uruchomieniu (streamlit run app.py) użytkownik widzi interfejs czatu z paskiem bocznym, w którym wybiera tematyczną kolekcję i model Ollama.
Na każde pytanie użytkownika system wykonuje następującą sekwencję:
- Pytanie jest zamieniane na wektor tą samą metodą embeddingową co dokumenty.
- Retriever przeszukuje kolekcję Qdrant i zwraca 5 najbliższych fragmentów tekstu (
k=5). - Fragmenty są łączone w jeden blok kontekstowy przez łańcuch
create_stuff_documents_chain. - Kontekst wraz z pytaniem trafia do lokalnego modelu językowego przez
create_retrieval_chain. - Model generuje odpowiedź, a aplikacja wyświetla listę unikalnych plików źródłowych w rozwijanej sekcji.
System prompt jest zaprojektowany rygorystycznie: model ma odpowiadać wyłącznie na podstawie dostarczonego kontekstu i wprost przyznawać się do braku wiedzy, jeśli fragmenty nie zawierają odpowiedzi. Eliminuje to problem halucynacji, który jest typowy dla modeli odpowiadających „z pamięci”.
„Jeśli dostarczony kontekst nie zawiera odpowiedzi na pytanie, powiedz wprost, że nie wiesz biorąc pod uwagę dostępne zasoby, zamiast zmyślać z własnej wiedzy treningowej.”
Obsługa modeli jest dynamiczna: aplikacja przy starcie odpytuje lokalny serwer Ollama przez REST API (http://localhost:11434/api/tags) i wypełnia listę wyboru dostępnymi modelami. Domyślnie skonfigurowany jest ministral3, ale użytkownik może przełączyć się na dowolny inny model zainstalowany lokalnie. Zmiana kolekcji automatycznie czyści historię czatu, aby uniknąć pomieszania kontekstu między różnymi tematykami.
Cachowanie i wydajność
Ważnym elementem app.py są dekoratory @st.cache_resource użyte przy inicjalizacji modelu embeddingów, klienta Qdrant i modelu LLM. Dzięki temu zasoby są tworzone tylko raz na czas działania aplikacji – kolejne zapytania nie przeładowują modeli. Lista dostępnych modeli Ollama jest cache’owana przez 60 sekund (@st.cache_data(ttl=60)), co pozwala na wykrycie nowo zainstalowanych modeli bez pełnego restartu.
Praktyczne zastosowania
Ta architektura jest przydatna wszędzie tam, gdzie użytkownik potrzebuje przeszukiwać prywatny lub firmowy zbiór dokumentów bez wysyłania ich do zewnętrznych API. Kilka konkretnych przypadków:
- Baza wiedzy technicznej: zaingestowanie dokumentacji produktów, instrukcji lub RFC pozwala na zadawanie pytań w języku naturalnym zamiast przeszukiwania PDF ręcznie.
- Asystent e-booków i książek: użytkownik może zbudować osobne kolekcje tematyczne (np. „programowanie”, „prawo”, „medycyna”) i przełączać się między nimi.
- Poufne dokumenty firmowe: całkowita lokalizacja – Qdrant na dysku, Ollama lokalnie – oznacza, że żadne dane nie opuszczają maszyny użytkownika.
- Prototypowanie RAG: prosta dwuplikowa struktura ułatwia eksperymentowanie z różnymi modelami embeddingów, rozmiarami chunków czy liczbą zwracanych fragmentów.
Ograniczenia i możliwe rozszerzenia
Obecna implementacja ma kilka technicznych ograniczeń, które warto uwzględnić przy planowaniu rozbudowy. Retriever używa prostego wyszukiwania wektorowego bez reranking ani filtrowania metadatowego, co może obniżać precyzję przy bardzo dużych kolekcjach. Rozmiar kontekstu (k=5 fragmentów po 1000 znaków to ok. 5000 znaków) jest stały – przy modelach z małym oknem kontekstowym może to powodować problemy. Warto też rozważyć zamianę create_stuff_documents_chain na create_map_reduce_documents_chain przy dużych zbiorach danych, gdzie kontekst nie mieści się w oknie modelu.
Możliwe kierunki rozbudowy obejmują m.in. dodanie filtrów metadatowych (np. wyszukiwanie tylko w konkretnym pliku), implementację hybrydowego wyszukiwania (wektor + keyword BM25), dodanie reranking modelu oraz eksport historii czatu do pliku. Qdrant obsługuje wszystkie te funkcjonalności na poziomie bazy danych, więc rozszerzenie dotyczyłoby głównie warstwy LangChain i interfejsu.
Repozytorium
Implementacja która została omówiona znajduje się na oficjalnym repozytorium lowcyai.
Źródła
- A Comprehensive Survey of Retrieval-Augmented Generation (RAG) – arXiv
- sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 – Hugging Face
- Qdrant Local Quickstart – qdrant.tech
- Comprehensive guide to Qdrant Vector DB – futuresmart.ai
- rag_pdf – repozytorium implementacji

