





Wprowadzenie
Klasyczne modele typu Transformer skalują się głównie przez dodawanie kolejnych warstw i parametrów, co szybko podnosi koszty obliczeń i pamięci. Mixture of Experts (MoE) wprowadza rzadką aktywację: dla każdego tokena uruchamiana jest tylko część parametrów, dzięki czemu model może mieć bardzo dużą pojemność, ale relatywnie niski koszt przetwarzania pojedynczego wejścia. W artykule Hugging Face opisano, jak taka architektura została włączona jako „pierwszy obywatel” do biblioteki Transformers – od formatu wag po warstwę wykonawczą.
Architektura MoE w modelach Transformer
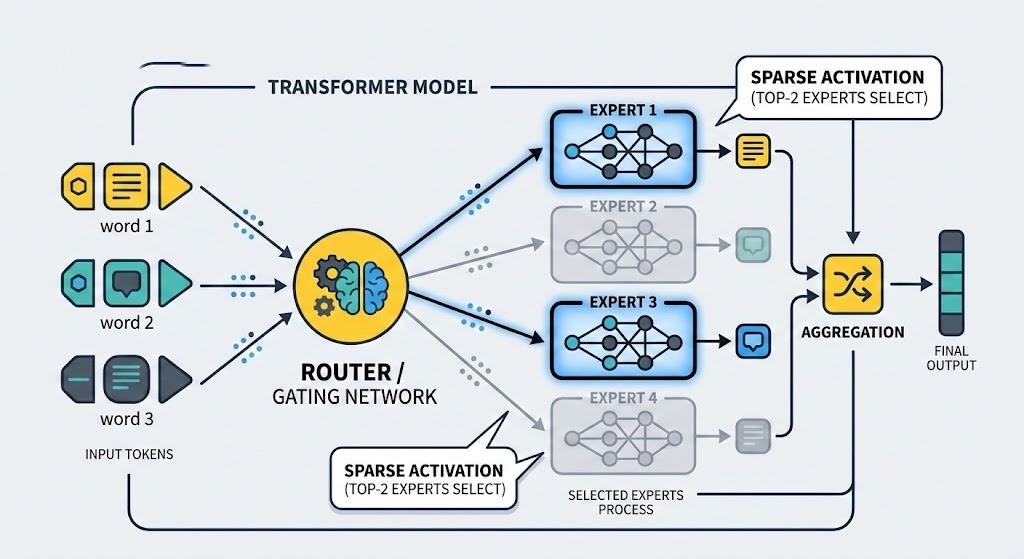
Model MoE zachowuje standardowy szkielet Transformera (warstwy uwagi, normalizacje, itp.), ale w wybranych miejscach klasyczną gęstą warstwę feed-forward (FFN/MLP) zastępuje blok składający się z wielu ekspertów. Każdy ekspert to oddzielna sieć (zwykle MLP) o tej samej strukturze, ale własnym zestawie wag, co pozwala specjalizować je do różnych typów danych lub wzorców. Dodatkowy komponent – router (bramka) – decyduje, które eksperty mają obsłużyć dany token, najczęściej wybierając top‑k ekspertów na podstawie wyników niewielkiej warstwy liniowej i softmax.
W efekcie dla pojedynczego tokena aktywna jest tylko niewielka część całkowitej liczby parametrów modelu, podczas gdy nominalna pojemność (łączna liczba wag wszystkich ekspertów) może być bardzo duża. Takie podejście stoi m.in. za modelami pokroju Mixtral 8x7B, które uzyskały dużą jakość przy istotnie mniejszym koszcie obliczeń w porównaniu z gęstymi modelami o podobnej jakości.
| Komponent | Rola w MoE w Transformers |
|---|---|
| Backbone Transformera | Utrzymuje standardowe bloki uwagi i ogólną strukturę warstw, stanowi wspólny „szkielet” modelu. |
| Eksperci (MLP) | Zastępują gęstą warstwę FFN zestawem wielu niezależnych MLP, z których każdy posiada własne wagi. |
| Router / bramka | Przypisuje tokeny do wybranych ekspertów (np. top‑k), wprowadzając rzadkość aktywacji. |
| Experts Backend | Warstwa wykonawcza decydująca, jak fizycznie uruchomić obliczenia ekspertów na dostępnym sprzęcie. |
Refaktoryzacja ładowania wag: rola WeightConverter
Modele MoE zawierają bardzo wiele tensorów wag – dla każdego eksperta osobny zestaw parametrów – co przy naiwnym ładowaniu znacząco podnosi szczytowe zużycie pamięci i czas startu. Aby to opanować, w Transformers wprowadzono refaktoryzację ładowania wag, opartą o komponent WeightConverter, który zajmuje się konwersją i układaniem tensorów ekspertów w zoptymalizowany sposób. Konwerter może np. scalić wagi wielu ekspertów w jeden bardziej „przyjazny” bufor, co zmniejsza narzut na alokacje i kopie w pamięci.
Dzięki temu ta sama logika ładowania może obsługiwać różne implementacje MoE, jeżeli tylko zdefiniujemy odpowiednią mapę konwersji między formatem checkpointu a wewnętrzną reprezentacją modelu w Transformers. W praktyce ułatwia to dodawanie nowych modeli MoE do ekosystemu i pozwala lepiej wykorzystać pamięć GPU/CPU, szczególnie podczas uruchamiania bardzo dużych konfiguracji ekspertów.
Experts Backend: pluggowalna warstwa wykonawcza
Kluczową nowością opisaną w artykule jest Experts Backend – system, który rozdziela implementację warstwy MoE od sposobu wykonywania obliczeń ekspertów. Zamiast kodować w każdym modelu jedną, sztywną strategię dystrybucji tokenów i uruchamiania ekspertów, biblioteka pozwala wybrać backend w czasie wykonania. Backend może implementować różne strategie, np. łączenie wielu wywołań MLP w jedną zgrupowaną operację GEMM (grouped GEMM), co istotnie poprawia wykorzystanie GPU.
Taki projekt umożliwia dostosowanie sposobu wykonania MoE do konkretnej konfiguracji sprzętowej i scenariusza: od pojedynczej karty GPU, przez wielokrotne GPU, po klastry. Jednocześnie sama definicja modelu pozostaje prosta – autor modelu skupia się na architekturze (liczba ekspertów, top‑k, miejsce wstawienia warstw MoE), a szczegóły niskopoziomowe (pakowanie batchy, organizacja macierzy, strategie komunikacji) przejmuje wybrany backend.
Równoległość ekspertów i praktyczne zastosowania
MoE szczególnie dobrze współgra z równoległością ekspercką (expert parallelism), w której różne eksperci są rozmieszczani na różnych urządzeniach, a router wysyła tokeny tam, gdzie znajduje się przypisany ekspert. Pozwala to trenować i obsługiwać modele o pojemności liczonych w setkach miliardów lub bilionach parametrów, nawet jeśli żadne pojedyncze urządzenie nie pomieściłoby wszystkich ekspertów jednocześnie. Według opisu Hugging Face, połączenie takiej równoległości z nową infrastrukturą backendów i optymalizacjami obliczeń istotnie przyspiesza trenowanie i umożliwia obsługę dłuższych kontekstów.
Z perspektywy praktycznej użytkownika biblioteki Transformers, MoE stają się pełnoprawnym elementem ekosystemu: można korzystać z gotowych modeli MoE, ładować je w sposób zbliżony do modeli gęstych i uruchamiać na różnych konfiguracjach sprzętowych, korzystając z domyślnych lub specjalistycznych backendów. Może to być szczególnie przydatne przy:
- budowie dużych modeli językowych o ograniczonym budżecie FLOPs, gdzie opłaca się mieć wielu ekspertów przy rzadkiej aktywacji;
- modelach wymagających długiego kontekstu, w których koszt pojedynczego kroku musi być ściśle kontrolowany;
- eksperymentach z wyspecjalizowanymi ekspertami (np. kod, języki niszowe, modalności), gdzie różne części modelu uczą się innych podzadań.
Istotne są też kompromisy: zyskujemy mniejszy koszt obliczeniowy na token i większą pojemność modelu, ale płacimy dodatkowymi kosztami routingu oraz komunikacji między urządzeniami przy rozproszonym uruchomieniu. Artykuł podkreśla, że dzięki nowej infrastrukturze (WeightConverter, Experts Backend, optymalizacje GEMM) te koszty są jednak znacząco łagodzone, co czyni MoE praktyczną alternatywą dla gęstych architektur w ekosystemie Hugging Face.
Źródła
- Mixture of Experts (MoEs) in Transformers – Hugging Face
- Mixture of Experts Explained – Hugging Face
- Evolution of Mixture of Experts in Transformers (omówienie artykułu HF)
- Mixture of Experts Architecture in Transformer Models – Machine Learning Mastery


