






Postęp w dziedzinie generowania obrazów z tekstu przyspiesza w zastraszającym tempie. Jeszcze kilka lat temu trening kompetetywnego modelu dyfuzyjnego wymagał miesięcy pracy i budżetów sięgających milionów dolarów. Dziś, dzięki optymalizacjom architektonicznym i treningowym, możliwe staje się uzyskanie użytecznych rezultatów w czasie jednej doby. Zespół Photoroom udowodnił to w trzeciej części serii PRX, prezentując kompletny pipeline treningowy, który zmieścił się w 24 godzinach na 32 kartach H200.
Kluczowe komponenty szybkiego treningu
Podstawą eksperymentu była architektura PRX (Photoroom Experimental) – 1.3-miliardowy model oparty na uproszczonej wariancie MMDiT, gdzie tokeny tekstowe nie są aktualizowane wewnątrz bloków transformera. Zamiast standardowego treningu w przestrzeni latentnej, zespół zastosował podejście inspirowane pracą PixelGen, trenując bezpośrednio na przestrzeni pikseli. Ta zmiana eliminuje narzut związany z kompresją VAE i pozwala modelowi uczyć się bezpośrednich reprezentacji wizualnych.
Do podstawowej straty dyfuzyjnej dodano dwie składowe percepcyjne: LPIPS (Learned Perceptual Image Patch Similarity) oraz stratę opartą na cechach DINOv2. Zastosowano je na poziomie pełnych obrazów (a nie pojedynczych patchy) oraz we wszystkich poziomach szumu, co okazało się bardziej efektywne w tym konkretnym ustawieniu. Kombinacja tych sygnałów przyspiesza zbieżność i poprawia końcową jakość wizualną.
Efektywność obliczeniowa przez routing tokenów
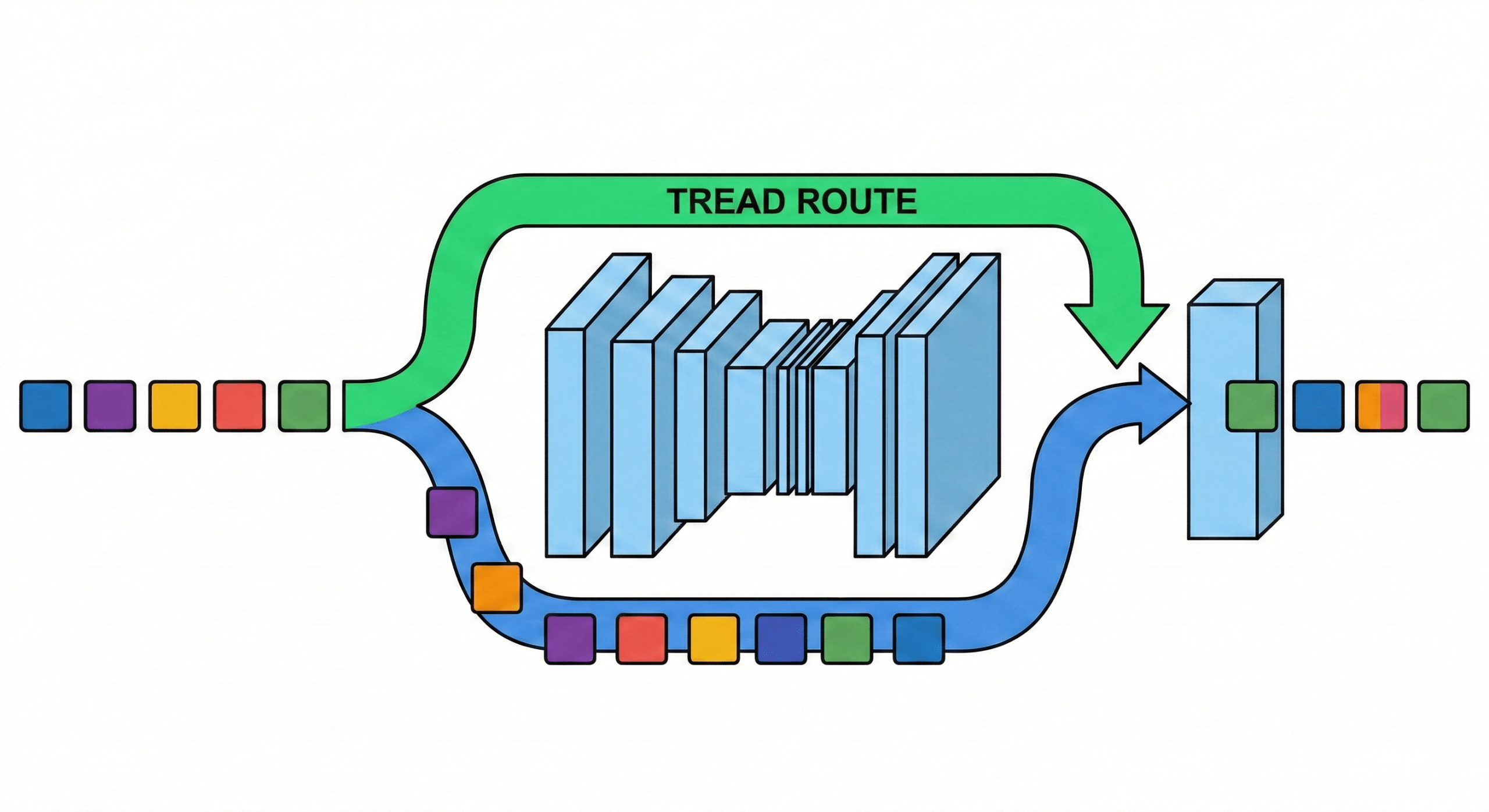
Jednym z najważniejszych usprawnień było wdrożenie mechanizmu TREAD (Token Routing for Efficient Architecture Design). W tej konfiguracji 50% tokenów z drugiego bloku transformera jest kierowanych bezpośrednio do przedostatniego bloku, pomijając pośrednie warstwy. To rozwiązanie znacząco redukuje obciążenie obliczeniowe bez proporcjonalnego spadku jakości.
Modele z routingiem tokenów często zachowują się gorzej przy standardowym Classifier-Free Guidance (CFG), szczególnie w wczesnych fazach treningu. Zespół zaimplementował więc mechanizm self-guidance oparty na porównaniu predykcji warunkowej z pełnym i zroutowanym przepływem tokenów. To podejście eliminuje potrzebę generowania oddziaływania bezwarunkowego, co dodatkowo przyspiesza inferencję.
Wyrównanie reprezentacji i optymalizacja
Kolejnym kluczowym elementem było zastosowanie REPA (Representation Alignment) z DINOv3 jako modelem nauczyciela. Technika ta wymusza zgodność reprezentacji wewnętrznych modelu dyfuzyjnego z encjami wyuczonymi przez duży model wizyjny, co przyspiesza uczenie semantycznych koncepcji. Do optymalizacji wykorzystano optymalizator Muon, który wykazuje lepszą zbieżność niż standardowe implementacje AdamW w zadaniach związanych z dużymi modelami transformera.
Proces treningu podzielono na trzy etapy progresywne: 8 godzin na rozdzielczości 256×256, kolejne 8 godzin na 512×512 i finałowy etap 1024×1024. Taki schedule pozwala modelowi najpierw nauczyć się globalnej kompozycji i semantyki, a następnie dodać detale wysokiej częstotliwości bez destabilizacji wcześniej wyuczonych reprezentacji.
Zestaw danych i praktyczne rezultaty

Do treningu wykorzystano trzy publicznie dostępne zbiory danych syntetycznych: Flux generated (1.7M próbek), FLUX-Reason-6M (6M próbek) oraz midjourney-v6-llava (1M próbek). Ten ostatni zbiór został przekaptionowany za pomocą Gemini 2.5 Flash w celu ujednolicenia stylu promptów i redukcji szumu w opisach.
Wyniki po 24 godzinach treningu są zaskakująco solidne. Model demonstruje dobre przestrzeganie promptów, spójną estetykę i poprawne renderowanie detali na poziomie 1024×1024. Oczywiście wciąż widać pewne artefakty tekstur, sporadyczne problemy z anatomią oraz trudności przy bardzo złożonych zapytaniach, ale jako punkt wyjścia dla dalszego treningu lub fine-tuningu pod konkretne zastosowania – jest to wynik więcej niż zadowalający.
Implikacje dla społeczności open source
Całość kodu, konfiguracji i frameworku eksperymentalnego została udostępniona na licencji Apache 2.0 w repozytorium GitHub Photoroom. Choć samych datasetów nie redystrybuowano, pipeline jest w pełni konfigurowalny i zaprojektowany z myślą o łatwej adaptacji do własnych danych. To otwiera drogę dla mniejszych zespołów badawczych i niezależnych deweloperów do eksperymentowania z dużymi modelami generatywnymi bez konieczności dysponowania korporacyjnymi budżetami.
Eksperyment PRX Part 3 pokazuje, że kombinacja treningu w przestrzeni pikseli, efektywnego routingu tokenów, wyrównania reprezentacji i lekkich strat percepcyjnych pozwala na znaczące skrócenie czasu treningu przy zachowaniu konkurencyjnej jakości. To sygnał, że demokratyzacja technologii generowania obrazów z tekstu postępuje w tempie, które jeszcze niedawno wydawało się niemożliwe.
Źródła
- PRX Part 3 — Training a Text-to-Image Model in 24h! – Hugging Face
- Photoroom/prx-1024-t2i-beta – Hugging Face
- Training Design for Text-to-Image Models: Lessons from Ablations – Hugging Face
- Photoroom/PRX – GitHub

